AI论文精选
强化学习
⏶
669
分享即关怀:利用集体 RL 经验共享进行高效 LM 后训练
⏶
418
DeepSeek-R1:通过强化学习激励LLM的推理能力
⏶
302
组序列策略优化
⏶
274
反思、重试、奖励:基于强化学习的LLM自我改进
⏶
233
通过早期经验进行代理学习
⏶
213
面向 LLM 的代理强化学习景观:一篇调查报告
⏶
185
GLM-4.5:智能体、推理和编码(ARC)基础模型
⏶
179
大型推理模型的强化学习调研
⏶
177
关于SFT泛化性的研究:一个带有奖励修正的强化学习视角
⏶
164
QeRL:超越效率——面向大型语言模型的量化增强强化学习
⏶
157
将RL扩展到长视频
⏶
153
自主强化策略优化
⏶
145
开放式生成的逆向工程推理
⏶
141
DAPO:大规模开源LLM强化学习系统
⏶
138
ProRL:长期强化学习拓展大型语言模型的推理边界
⏶
135
WebWatcher:突破视觉语言深度研究代理新前沿
⏶
132
Vision-Zero:通过策略性游戏化自对弈实现可扩展的VLM自我改进
⏶
131
置信度即所需一切:语言模型的少样本强化学习微调
⏶
131
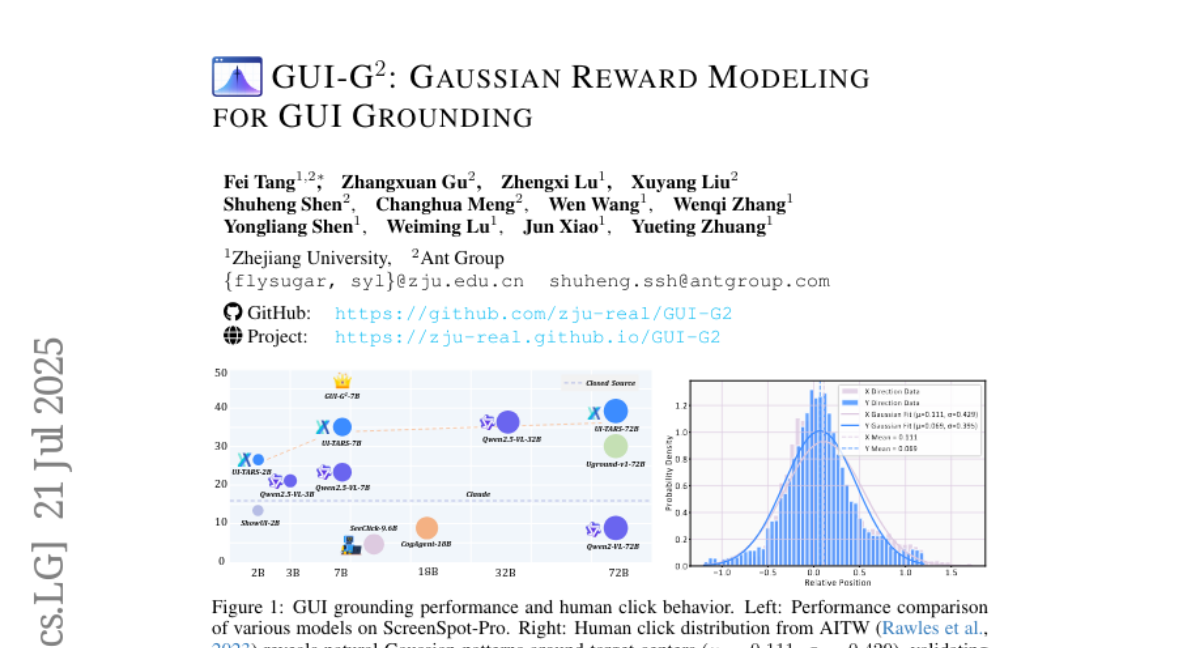
GUI-G^2:用于GUI对齐的高斯奖励建模
⏶
130
用于推理语言模型的强化学习熵机制
⏶
130
快手 Keye-VL 技术报告
⏶
126
EPO:熵正则化策略优化用于 LLM 智能体强化学习
⏶
121
UI-TARS-2 技术报告:通过多轮强化学习推进 GUI 代理
⏶
116
ReasonRank:通过强大的推理能力赋能段落排序
⏶
113
灵枢:面向统一多模态医学理解与推理的通用基础模型
⏶
112
Seed-Prover:用于自动定理证明的深度和广度推理
⏶
104
FlowRL: 匹配LLM推理的奖励分布
⏶
98
Parallel-R1:通过强化学习实现并行思考
⏶
96
使用一个训练样本对大型语言模型进行推理的强化学习
⏶
96
SciReasoner: 奠定跨学科的科学推理基础
⏶
95
MMaDA: 多模态大型扩散语言模型
⏶
94
Table-R1:面向表格推理的推理时缩放
⏶
93
SSRL: 自搜索强化学习
⏶
89
Pref-GRPO:基于成对偏好奖励的GRPO,用于稳定的文本到图像强化学习
⏶
89
在流式代理系统中优化以实现有效的规划和工具使用
⏶
88
学习在离策略指导下进行推理
⏶
88
QwenLong-L1:迈向基于强化学习的长上下文大型推理模型
⏶
88
SWE-rebench:软件工程智能体任务收集与去污评估的自动化管线
⏶
88
推理还是记忆化?数据污染导致的强化学习结果不可靠
⏶
86
用于 LLM 代理强化学习的树搜索
⏶
84
通过推理分解实现自奖励的视觉语言模型
⏶
83
LLaVA-Critic-R1:你的批评模型秘密是一个强大的策略模型
⏶
83
SimpleTIR:用于多轮工具集成推理的端到端强化学习
⏶
82
MiMo:释放语言模型的推理潜力——从预训练到后训练
⏶
80
TreePO:通过启发式树形建模弥合策略优化、有效性和推理效率之间的差距
⏶
80
机器人学习:教程
⏶
79
数学推理能否提升通用LLM能力?理解LLM推理的可迁移性
⏶
78
WebExplorer:用于训练长时序网页代理的探索与演进
⏶
76
SimpleVLA-RL: 通过强化学习扩展 VLA 训练
⏶
75
VisionThink:通过强化学习实现的智能高效视觉语言模型
⏶
73
迈向大型语言模型训练后统一视角
⏶
72
REASONING GYM:推理环境,用于具备可验证奖励的强化学习
⏶
70
Agent Lightning:使用强化学习训练任意AI智能体
⏶
65
ZeroSearch:无需搜索即可激发 LLMs 的搜索能力
⏶
65
更多思考,更少准确性?论视觉语言模型中推理的双重性质
⏶
64
马吉斯特拉
⏶
64
预训练数据上的强化学习
⏶
63
MMSearch-R1:激励LMM进行搜索
⏶
63
VLA-RFT:在世界模拟器中具有验证奖励的视觉-语言-动作强化微调
⏶
62
ReTool:用于LLM中战略工具使用的强化学习
⏶
62
扩展推理,失去控制:评估大型推理模型中的指令遵循能力
⏶
61
TaTToo:用于表格推理中测试时间扩展的工具接地思维 PRM
⏶
59
视觉三元统一强化学习:一种强化学习看遍所有
⏶
59
Mini-o3:扩展用于视觉搜索的推理模式和交互回合
⏶
58
AdaCoT:基于强化学习的帕累托最优自适应思维链触发
⏶
57
Reasoning Vectors:通过任务算术转移思维链能力
⏶
56
Tina:通过 LoRA 实现的微小推理模型
⏶
56
视觉规划:只用图像思考
⏶
56
LongWriter-Zero:通过强化学习掌握超长文本生成
⏶
56
ARC-混元-视频-7B:真实世界短视频的结构化视频理解
⏶
55
观看、聆听、记忆和推理:一个拥有长期记忆的多模态智能体
⏶
55
AgentGym-RL:通过多轮强化学习训练 LLM 智能体以进行长视界决策
⏶
55
大型推理模型从错误思考中学习更好的对齐
⏶
54
DeepCritic:使用大型语言模型进行审慎批判
⏶
54
Skywork Open Reasoner 1 技术报告
⏶
54
注意力照亮大模型推理:预规划与锚定节奏赋能细粒度策略优化
⏶
53
Pixel Reasoner: 通过好奇心驱动的强化学习激励像素空间推理
⏶
53
ComfyUI-R1: 探索用于工作流生成的推理模型
⏶
52
UniVG-R1: 结合强化学习的推理引导通用视觉定位
⏶
52
SynthRL:通过可验证数据合成扩展视觉推理
⏶
51
TruthRL:通过强化学习激励诚实的LLM
⏶
50
Thinkless:大语言模型学习何时思考
⏶
50
SPIRAL:通过零和博弈上的自博弈,利用多智能体多回合强化学习激励推理
⏶
49
从跨域视角再探用于大语言模型推理的强化学习
⏶
48
Phi-4-Mini-Reasoning:探索小型推理语言模型在数学领域的极限
⏶
48
SRPO:通过反思感知强化学习增强多模态大语言模型推理
⏶
48
可追溯证据增强的视觉接地推理:评估与方法
⏶
48
Robix:机器人交互、推理和规划的统一模型
⏶
47
ToolRL:奖励是工具学习的全部需求
⏶
47
FlowReasoner:增强查询级元代理
⏶
47
OctoThinker:训练中期激励强化学习扩展
⏶
47
UI-S1:通过半在线强化学习推进 GUI 自动化
⏶
46
通过 GRPO 对多模态 LLM 推理进行无监督后训练
⏶
46
VL-Cogito:用于高级多模态推理的渐进式课程强化学习
⏶
46
第一部分:是技巧还是陷阱?深入探讨用于大型语言模型推理的强化学习
⏶
46
背包强化学习:通过优化预算分配实现大型语言模型探索的解锁
⏶
45
ZeroGUI:以零人力成本自动化在线GUI学习
⏶
45
使用大型语言模型进行符号图形编程
⏶
44
T2I-R1:协同语义级和词元级CoT强化图像生成
⏶
44
Video-LMM 训练后:深入了解大型多模态模型的视频推理
⏶
43
使用语言模型学习自适应并行推理
⏶
43
HardTests:为LLM编码合成高质量测试用例
⏶
43
Ego-R1:用于超长第一人称视频推理的工具思维链
⏶
43
CriticLean: 评论家引导的强化学习,用于数学形式化
⏶
42
Llama-Nemotron: 高效推理模型