⏶40
OctoThinker:训练中期激励强化学习扩展
发表
由  Zengzhi Wang 提交
Zengzhi Wang 提交
Zengzhi Wang 提交作者: Zengzhi Wang,  Fan Zhou, Xuefeng Li,
Fan Zhou, Xuefeng Li,  Pengfei Liu
Pengfei Liu
Zengzhi Wang, Fan Zhou, Xuefeng Li, Pengfei Liu摘要
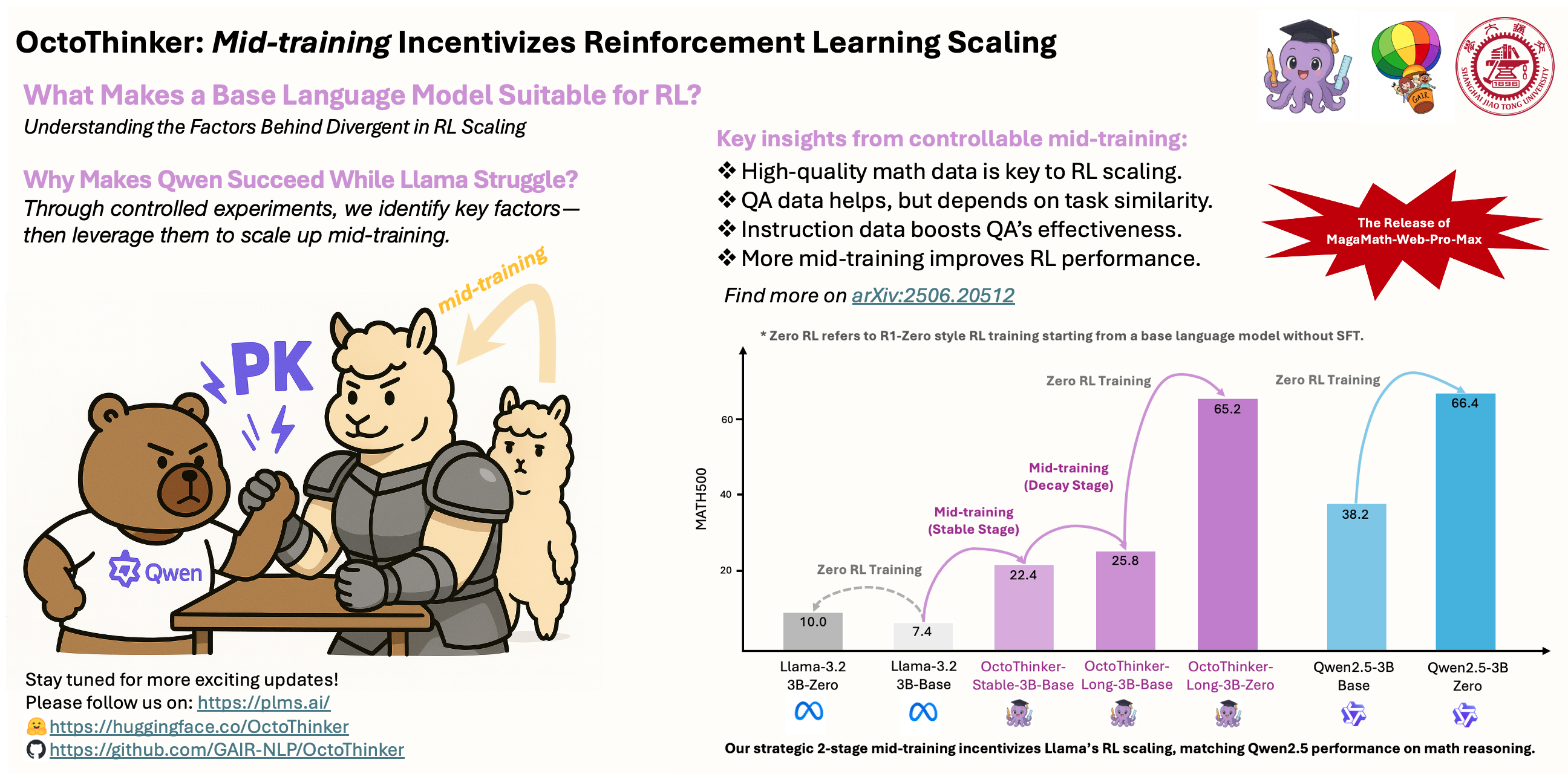
不同的基础语言模型家族,如Llama和Qwen,在强化学习(RL)后训练过程中表现出不同的行为,尤其是在推理密集型任务上。什么使得基础语言模型适合强化学习?深入了解这个问题对于开发下一代可扩展RL的基础模型至关重要。在这项工作中,我们研究了中期训练策略如何影响RL动态,重点关注两个代表性模型家族:Qwen和Llama。我们的研究表明:(1)高质量的数学语料库,如MegaMath-Web-Pro,显著提升了基础模型和RL的性能,而现有替代品(例如FineMath-4plus)则未能做到;(2)进一步添加问答式数据,特别是长链式思考(CoT)推理示例,能增强RL结果,并且指令数据进一步释放了这一效果;(3)虽然长CoT能提高推理深度,但它也可能导致模型响应冗长以及RL训练的不稳定性,这突显了数据格式化的重要性;(4)中期训练的扩展始终能带来更强的下游RL性能。基于这些见解,我们引入了一种两阶段中期训练策略——Stable-then-Decay,其中基础模型首先以恒定学习率在2000亿个token上进行训练,随后在三个以CoT为重点的分支上,以学习率衰减的方式,在200亿个token上进行训练。这产生了OctoThinker模型家族,该家族展示了强大的RL兼容性,并缩小了与更适合RL的模型家族(即Qwen)的性能差距。我们希望我们的工作能有助于塑造RL时代基础模型的预训练策略。为了支持进一步的研究,我们发布了我们的开源模型以及一个精选的、超过700亿token的数学推理密集型语料库(即MegaMath-Web-Pro-Max)。
在我们的HF组织上查看更多发布:https://huggingface.co/OctoThinker
敬请期待。