AI论文精选
大型语言模型
⏶
341
A.S.E:评估人工智能生成代码安全性的存储库级别基准
⏶
302
组序列策略优化
⏶
299
Qwen3 技术报告
⏶
256
大型语言模型的语境工程综述
⏶
207
胡言乱语学:用深度解读胡言乱语挑战大型语言模型
⏶
183
超越二八法则:高熵少数词元驱动LLM推理中的有效强化学习
⏶
179
大型推理模型的强化学习调研
⏶
153
MemOS: 专为AI系统设计的内存操作系统
⏶
153
自主强化策略优化
⏶
144
将AI效率从模型中心转向数据中心压缩
⏶
139
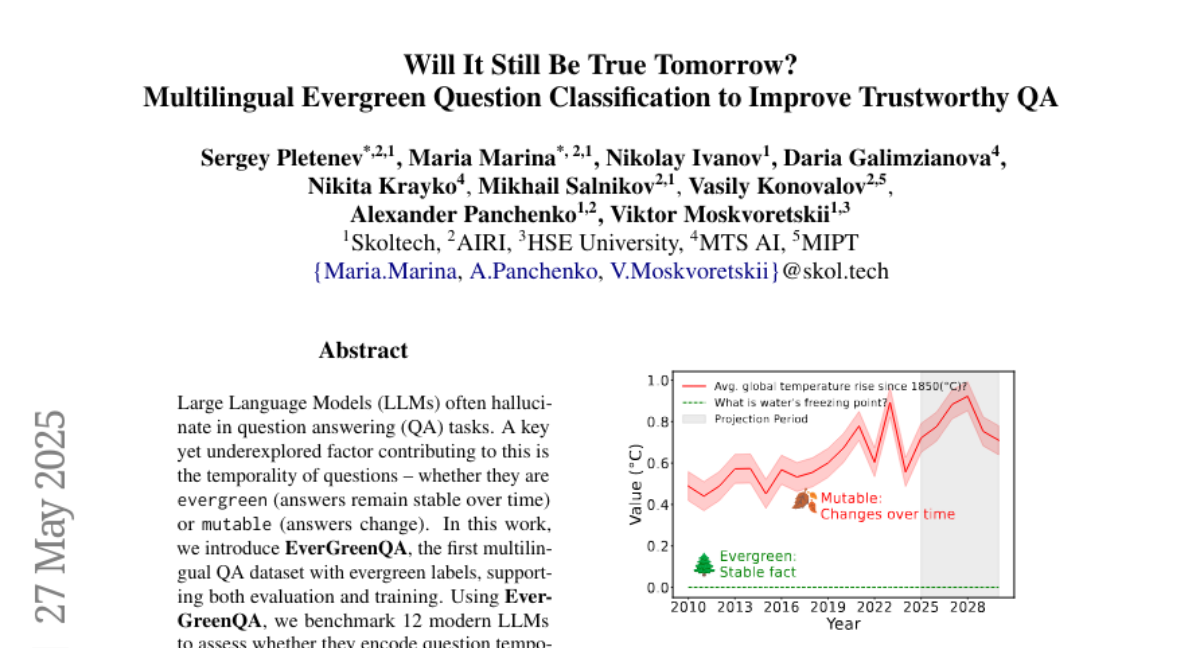
明天它还会是真的吗?多语言常青问题分类以提高可信问答
⏶
136
PRIMA.CPP:加速低资源日常家庭集群上700亿参数规模LLM的推理
⏶
131
置信度即所需一切:语言模型的少样本强化学习微调
⏶
127
Chain-of-Agents:通过多智能体蒸馏和智能体强化学习实现端到端智能体基础模型
⏶
126
拖放式LLM:零样本提示到权重
⏶
123
面向大语言模型推理:内部概率与自洽性桥接的理论研究
⏶
120
Paper2Code:从机器学习科学论文中自动化生成代码
⏶
110
通过持续预训练扩展代理
⏶
109
WideSearch:对代理广域信息搜索的基准测试
⏶
105
LongCodeZip:压缩代码语言模型的长上下文
⏶
105
当模型说谎时,我们学习:使用 PsiloQA 进行多语言跨度级幻觉检测
⏶
96
使用一个训练样本对大型语言模型进行推理的强化学习
⏶
94
DITING:用于基准测试网络小说翻译的多代理评估框架
⏶
93
SSRL: 自搜索强化学习
⏶
93
视频模型是零样本学习者和推理者
⏶
91
Cache-to-Cache:大型语言模型之间的直接语义通信
⏶
89
在流式代理系统中优化以实现有效的规划和工具使用
⏶
88
推理还是记忆化?数据污染导致的强化学习结果不可靠
⏶
86
用于 LLM 代理强化学习的树搜索
⏶
84
迈向具有深度推理能力的智能体RAG:LLM中RAG-推理系统综述
⏶
83
GEM:用于Agentic LLM的Gym
⏶
81
利用检索和代码工具将LLM智能体蒸馏到小模型
⏶
78
WebExplorer:用于训练长时序网页代理的探索与演进
⏶
77
Quartet: 对于大型语言模型,原生的 FP4 训练可以是最佳的
⏶
74
开放视觉推理器:迁移语言认知行为以实现视觉推理
⏶
73
SINQ:用于无校准低精度 LLM 权重的 Sinkhorn-归一化量化
⏶
71
FineWeb2: 一个管道,万物皆可扩展 —— 适配每种语言的预训练数据处理
⏶
70
Skywork-R1V3 技术报告
⏶
70
Agent Lightning:使用强化学习训练任意AI智能体
⏶
69
通过环境扩展迈向通用智能代理
⏶
69
Ming-UniVision:使用统一的连续分词器联合进行图像理解和生成
⏶
66
赢得剪枝赌局:统一的方法,用于高效监督微调的联合样本和令牌剪枝
⏶
65
Falcon-H1:重新定义效率与性能的混合头语言模型家族
⏶
64
推理模型很顽固: 诊断推理模型中的指令覆盖
⏶
64
预训练数据上的强化学习
⏶
63
扩展LLM智能体的测试时计算能力
⏶
63
MachineLearningLM:在数百万个合成表格预测任务上继续预训练语言模型,实现上下文学习的规模化
⏶
62
BizFinBench:一个用于评估大型语言模型的业务驱动型真实世界金融基准
⏶
62
MCP-Bench:通过MCP服务器对使用工具的LLM Agent进行复杂现实世界任务的基准测试
⏶
61
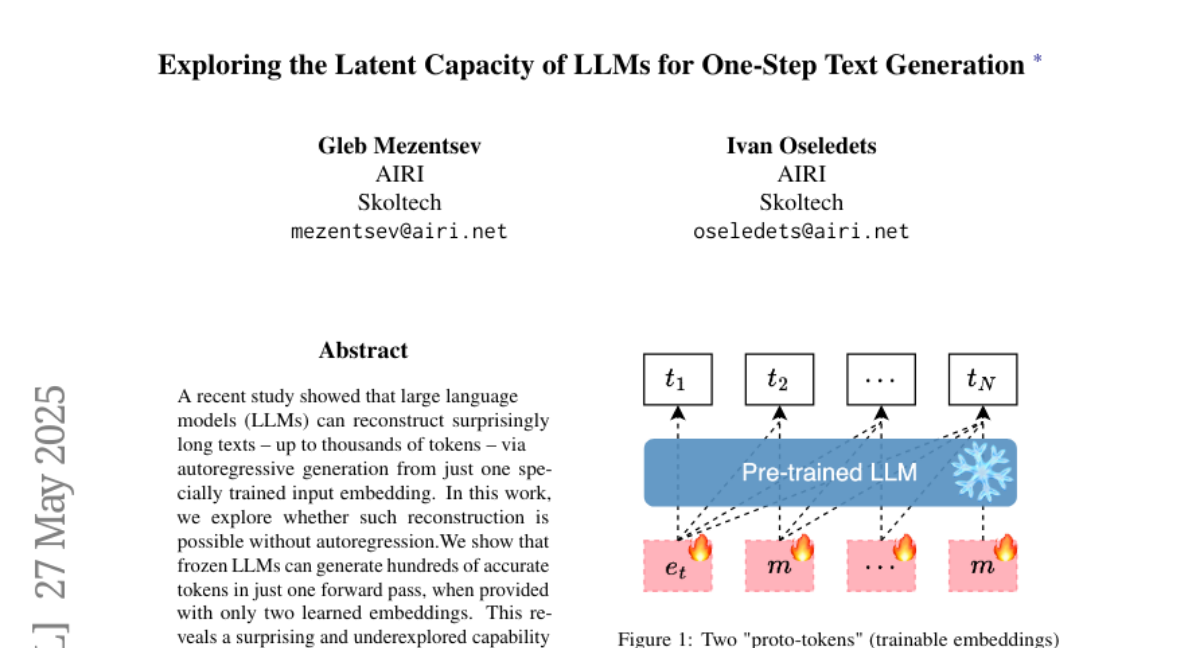
探索大型语言模型在一步文本生成中的潜在能力
⏶
60
多人纳什偏好优化
⏶
58
从分数到技能:评估金融大语言模型的认知诊断框架
⏶
57
逆IF评估:大型语言模型能否忘记顽固的训练惯例以遵循真实指令?
⏶
56
视觉规划:只用图像思考
⏶
56
Tool-Star: 通过强化学习赋能具备LLM大脑的多工具推理器
⏶
56
LongWriter-Zero:通过强化学习掌握超长文本生成
⏶
54
Skywork-Reward-V2:通过人机协同扩展偏好数据管理
⏶
54
注意力照亮大模型推理:预规划与锚定节奏赋能细粒度策略优化
⏶
52
SWE-Factory:用于问题解决训练数据和评估基准的自动化工厂
⏶
52
跨界推理:通过测试时权衡提高规范对齐
⏶
51
Mind2Web 2:使用代理即评审评估代理式搜索
⏶
51
AgentScope 1.0:一个以开发者为中心的框架,用于构建 Agentic 应用
⏶
51
TruthRL:通过强化学习激励诚实的LLM
⏶
51
DeepAnalyze:用于自主数据科学的智能体大型语言模型
⏶
50
DesignLab:通过迭代检测和纠正设计幻灯片
⏶
49
大型语言模型用于数据合成
⏶
48
Phi-4-Mini-Reasoning:探索小型推理语言模型在数学领域的极限
⏶
48
Easy Dataset:一个用于从非结构化文档中合成LLM微调数据的统一且可扩展的框架
⏶
48
Fast-dLLM v2:高效的块扩散 LLM
⏶
47
BitNet v2:原生4比特激活与哈达玛变换,用于1比特大型语言模型
⏶
47
代码图模型 (CGM):一种集成图的大语言模型,用于代码仓库级软件工程任务
⏶
47
AmbiK:厨房环境中的歧义任务数据集
⏶
47
感知感知的多模态推理策略优化
⏶
47
StockBench:LLM智能体能否在真实市场中进行盈利性的股票交易?
⏶
46
The Common Pile v0.1:一个包含 8TB 公有领域和开放许可文本的数据集
⏶
46
MUR: 动量不确定性引导推理用于大型语言模型
⏶
46
多模态提示优化:为什么不利用多种模态来优化 MLLMs
⏶
43
QwenLong-CPRS: 迈向具有动态上下文优化的无限长LLM
⏶
43
Enigmata:使用合成可验证谜题扩展大型语言模型的逻辑推理能力
⏶
42
SWE-Perf:语言模型能否在真实世界的代码仓库中优化代码性能?
⏶
42
Mol-R1:迈向分子发现中明确的长链思维推理
⏶
42
MCP-宇宙:使用真实世界模型上下文协议服务器对大型语言模型进行基准测试
⏶
42
先学习看,再去看:揭示语言预训练的LLM视觉先验
⏶
41
Xolver:通过整体经验学习进行多智能体推理,就像奥林匹克竞赛团队一样
⏶
40
LLM 量化的几何学:GPTQ 作为 Babai 最近平面算法
⏶
40
Glyph: 通过视觉文本压缩扩展上下文窗口
⏶
39
大型语言模型推理引擎综述:优化与效率的视角
⏶
39
VideoReasonBench:MLLM能否执行以视觉为中心的复杂视频推理?
⏶
39
GenRecal:从大到小视觉语言模型校准后生成
⏶
39
复杂逻辑指令生成
⏶
39
当标点符号至关重要时:LLM 提示鲁棒性方法的大规模比较
⏶
39
Baichuan-M2:使用大型验证器系统扩展医疗能力
⏶
39
SIM-CoT: 监督隐式思维链
⏶
39
不落下任何提示:通过熵引导的优势塑造,在LLM强化学习中利用零方差提示
⏶
38
驯服LLM:通过梯度分组缩放学习率
⏶
37
迈向评估性思维:伴随演化奖励模型的元策略优化
⏶
37
奖励推理模型
⏶
37
RecGPT 技术报告
⏶
37
LaSeR:基于最后一个词自我奖励的强化学习
⏶
36
对比偏好优化:在机器翻译中突破LLM性能的界限
⏶
36
PHYBench:大语言模型的物理感知与推理综合评估
⏶
36
解读轨迹辅助的LLM推理:一个优化视角
⏶
36
通过带有冷启动的强化学习推进多模态推理
⏶
36
RiemannLoRA: 用于无歧义 LoRA 优化的统一黎曼框架
⏶
35
DoLa:通过对比层解码提高大型语言模型的真实性