⏶27
SWE-Perf:语言模型能否在真实世界的代码仓库中优化代码性能?
发表
由  Qian Liu 提交
Qian Liu 提交
Qian Liu 提交作者:  Xinyi He, Qian Liu,
Xinyi He, Qian Liu,  Mingzhe Du, Lin Yan, Zhijie Fan, Yiming Huang, Zejian Yuan, Zejun Ma
Mingzhe Du, Lin Yan, Zhijie Fan, Yiming Huang, Zejian Yuan, Zejun Ma
Xinyi He, Qian Liu, Mingzhe Du, Lin Yan, Zhijie Fan, Yiming Huang, Zejian Yuan, Zejun Ma摘要
在现实世界的软件工程中,代码性能优化至关重要,并且对于生产级系统也是关键。虽然大语言模型 (LLM) 在代码生成和错误修复方面展现了令人印象深刻的能力,但它们在代码仓库级别提升代码性能的熟练程度在很大程度上仍未被探索。为了填补这一空白,我们推出了 SWE-Perf,这是首个专门设计用于在真实的代码仓库环境中系统性评估 LLM 在代码性能优化任务上表现的基准。SWE-Perf 包含 140 个精心筛选的实例,每个实例都源自热门 GitHub 代码仓库中提升性能的拉取请求。每个基准实例都包括相关的代码库、目标函数、性能相关的测试、专家编写的补丁和可执行环境。通过对涵盖文件级和代码仓库级方法(例如 Agentless 和 OpenHands)的代表性方法进行全面评估,我们揭示了现有 LLM 与专家级优化性能之间存在巨大的能力差距,凸显了这一新兴领域中的关键研究机会。
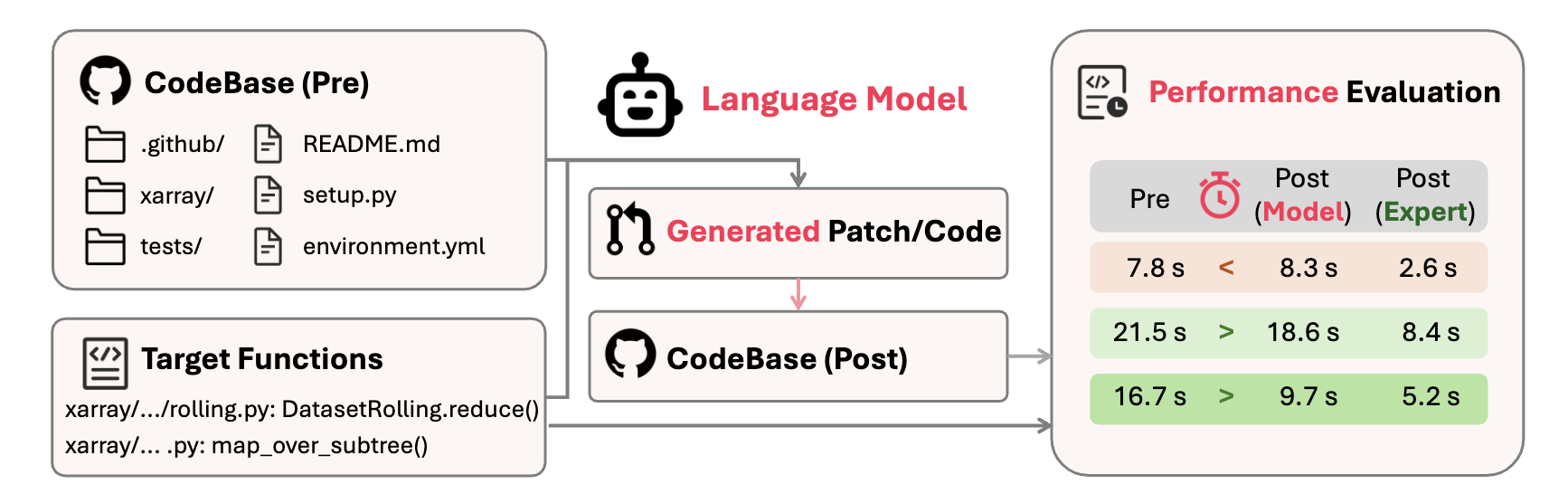
SWE-Perf 通过提供首个专注于实际代码性能优化的仓库级别数据集,解决了当前基准测试中的一个关键空白。