AI论文精选
GRPO
⏶
302
组序列策略优化
⏶
116
VCRL: 用于大型语言模型的基于方差的课程强化学习
⏶
116
用于熵安全推理的分位数优势估计
⏶
109
Ovis2.5 技术报告
⏶
104
FlowRL: 匹配LLM推理的奖励分布
⏶
96
使用一个训练样本对大型语言模型进行推理的强化学习
⏶
94
Table-R1:面向表格推理的推理时缩放
⏶
93
统一的多模态思维链奖励模型:通过强化微调实现
⏶
89
Pref-GRPO:基于成对偏好奖励的GRPO,用于稳定的文本到图像强化学习
⏶
83
GEM:用于Agentic LLM的Gym
⏶
77
ReSum:通过上下文摘要解锁长视线搜索智能
⏶
73
Fathom-DeepResearch:解锁长时域信息检索和 SLM 的综合利用
⏶
68
Spatial-MLLM:提升MLLM在基于视觉的空间智能方面的能力
⏶
67
语言模型的变分推理
⏶
56
视觉规划:只用图像思考
⏶
55
元意识增强推理模型:自对齐强化学习
⏶
51
TruthRL:通过强化学习激励诚实的LLM
⏶
47
感知感知的多模态推理策略优化
⏶
46
通过 GRPO 对多模态 LLM 推理进行无监督后训练
⏶
46
第一部分:是技巧还是陷阱?深入探讨用于大型语言模型推理的强化学习
⏶
44
ARM:自适应推理模型
⏶
39
Baichuan-M2:使用大型验证器系统扩展医疗能力
⏶
39
不落下任何提示:通过熵引导的优势塑造,在LLM强化学习中利用零方差提示
⏶
36
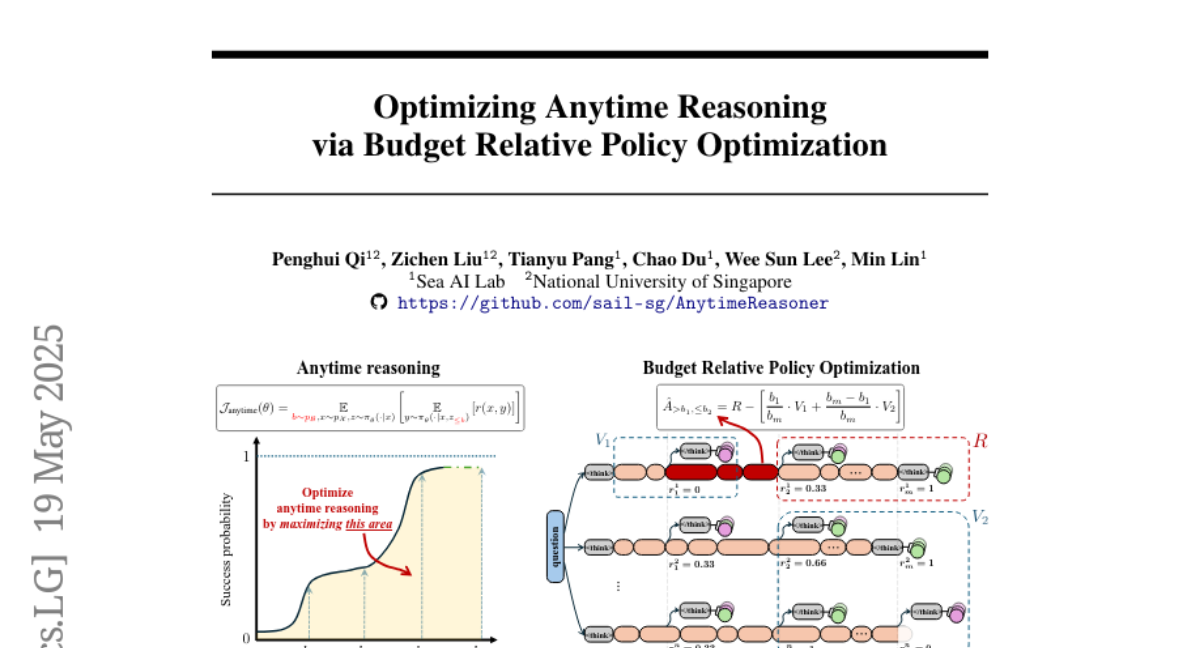
基于预算相对策略优化的随时推理优化
⏶
36
通过带有冷启动的强化学习推进多模态推理
⏶
36
CODA:通过解耦强化学习协调大脑和 cerebellum,用于双脑电脑使用代理
⏶
36
RLinf-VLA:一个统一高效的 VLA+RL 训练框架
⏶
35
OTC:基于强化学习的最优工具调用
⏶
33
单流策略优化
⏶
33
无需标签即可进化语言模型:多数驱动选择,新颖性促进变异
⏶
31
RLVER: 具有可验证情感奖励的强化学习,用于共情智能体
⏶
31
几何平均策略优化
⏶
30
借助工具强化视觉感知
⏶
30
通过强化学习实现大型语言模型的涌现式分层推理
⏶
28
GEPA:反思式提示演进可超越强化学习
⏶
28
对于具有可验证奖励的 LLM 推理,随机策略评估就足够了
⏶
26
通过弹性推理的可扩展思维链
⏶
25
通过拒绝采样和强化学习中的梯度方差最小化来优化思维链推理器
⏶
25
通过监督学习框架实现 RLVR 的隐式 Actor-Critic 耦合
⏶
24
CPGD: 迈向用于语言模型的稳定基于规则强化学习
⏶
23
VLM中针对图像偏好的听众奖励式思维
⏶
21
DCPO:动态裁剪策略优化
⏶
21
保持在最佳状态:通过能力自适应提示脚手架实现响应式推理演化
⏶
20
AV-Reasoner:改进和基准测试 MLLM 的线索导向音视频计数
⏶
19
DUMP:基于RL的LLM后训练的自动化分布级别课程学习
⏶
19
LLM推理的极简主义方法:从拒绝采样到强化学习
⏶
19
VOGUE:利用视觉不确定性指导探索以提升多模态推理能力
⏶
18
WirelessMathLM:使用强化学习为无线通信中的 LLM 教授数学推理
⏶
17
StreamBP:LLM 长序列训练的内存高效精确反向传播
⏶
17
使用 GRPO 提升语音感知语言模型中的语音理解能力
⏶
16
借星引航:大型语言模型在后训练和测试阶段扩展中从奖励中学习的综述
⏶
15
Active-O3:通过 GRPO 赋予多模态大语言模型主动感知能力
⏶
15
3D-R1:增强 3D 视觉语言模型中的推理能力以实现统一场景理解
⏶
15
用于扩散大语言模型的图像修复引导策略优化
⏶
14
通过强化学习实现的大型语言模型交错推理
⏶
13
DeepVideo-R1:通过难度感知回归式GRPO进行视频强化微调
⏶
13
自由形式生成中开放式R1训练的语义感知奖励
⏶
13
增加采样,减少思考:用于简洁推理的组过滤策略优化
⏶
13
通过动态奖励权重学习优化多目标对齐
⏶
13
Don't Waste Mistakes: 利用置信度重加权,从负强化学习组中汲取教训
⏶
12
DianJin-R1:评估与增强大型语言模型中的金融推理能力
⏶
12
让RL重拾价值:统一大模型推理器与验证器,提升推理时扩展性
⏶
12
GRIT: 教导MLLMs使用图像进行思考
⏶
11
强化学习微调大语言模型中的小子网络
⏶
11
TempFlow-GRPO: 流动模型中 GRPO 的时效性研究
⏶
11
Humanline:在线对齐作为感知损失
⏶
10
VisualSphinx:用于强化学习 (RL) 的大规模合成视觉逻辑谜题
⏶
10
优化大型推理模型中的长度压缩
⏶
10
构建数学大语言模型的实用两阶段方案:利用SFT最大化准确率,以强化学习提升效率
⏶
10
用于推理任务的混合专家语言模型的最优稀疏性
⏶
10
通过直接分组偏好优化强化扩散模型
⏶
9
Omni-R1:你真的需要音频来微调你的音频大语言模型吗?
⏶
9
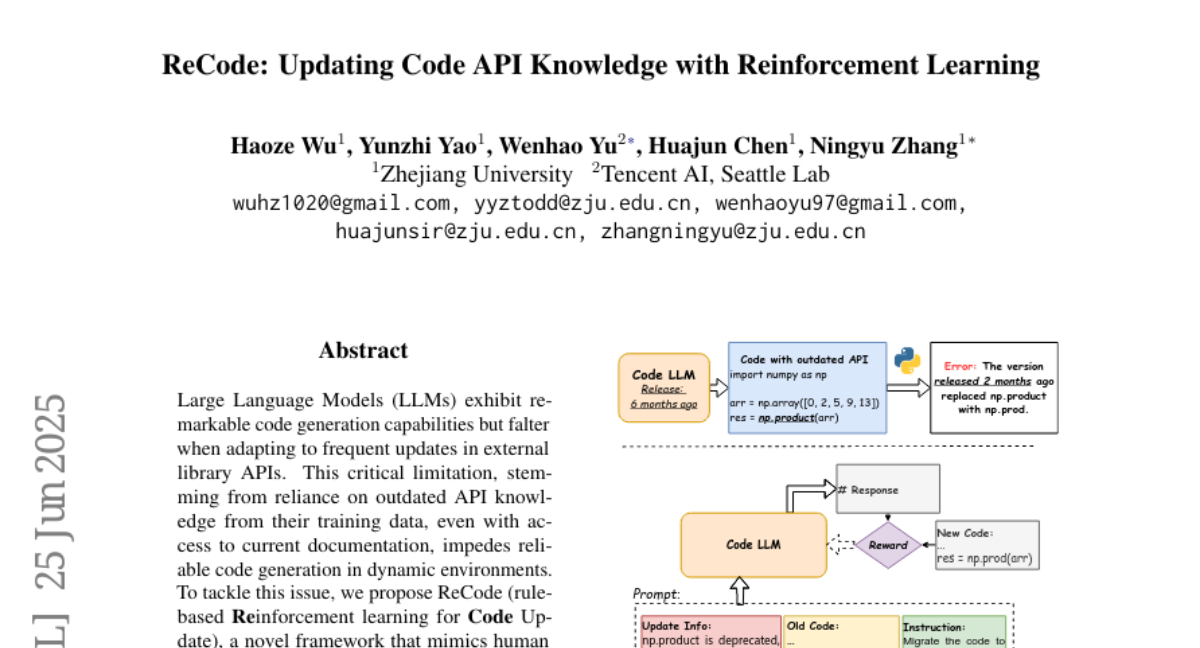
ReCode:基于强化学习更新代码API知识
⏶
9
GRPO-MA:GRPO 中的多答案生成,用于稳定高效的思维链训练
⏶
9
技能定向自适应训练
⏶
8
EDGE-GRPO:基于熵驱动的GRPO及引导式误差校正,实现优势多样性
⏶
7
ΔL归一化:重新思考RLVR中的损失聚合
⏶
6
关于用于LLM推理的KL正则化策略梯度算法的设计
⏶
6
选择性了解:一种用于领域特定问答的内部-外部知识自选框架
⏶
6
Group-Relative REINFORCE实际上是一个离线策略算法:揭示GRPO及其同类的一些神话
⏶
5
多轮主体式强化学习实践指南
⏶
5
G^2RPO:用于流模型中精确奖励的粒度GRPO
⏶
4
在数学推理中衔接监督学习与强化学习
⏶
4
面向对话代理的多模态策略内化
⏶
3
分段策略优化:大型语言模型强化学习中有效的段级信用分配
⏶
3
GeometryZero: 通过群组对比策略优化改进大语言模型的几何解题能力
⏶
3
对齐质量指数 (AQI):超越拒绝:AQI作为一种通过潜在几何、聚类发散和逐层池化表示的内在对齐诊断方法
⏶
3
推动 LLM 推理的边界
⏶
2
R1-代码解释器:通过监督学习和强化学习训练大型语言模型进行代码推理
⏶
2
巩固多模态离散扩散模型的强化学习
⏶
1
BOW:瓶颈式后续词探索
⏶
1
ReFIne:一个具有可靠性、忠实性和可解释性的可信大型推理模型框架