⏶35
基于预算相对策略优化的随时推理优化
发表
由  Penghui Qi 提交
Penghui Qi 提交
Penghui Qi 提交作者: Penghui Qi,  Zichen Liu,
Zichen Liu,  Tianyu Pang,
Tianyu Pang,  Chao Du, Wee Sun Lee, Min Lin
Chao Du, Wee Sun Lee, Min Lin
Penghui Qi, Zichen Liu, Tianyu Pang, Chao Du, Wee Sun Lee, Min Lin摘要
扩展推理时的计算资源对于提升大型语言模型(LLM)的推理能力至关重要。现有方法通常采用强化学习(RL),以最大化在推理过程结束时获得的可验证奖励。然而,这些方法仅在大而固定的 token 预算下优化最终性能,这阻碍了训练和部署的效率。在本文中,我们提出了一种新颖的框架 AnytimeReasoner,用于优化随时推理性能,旨在提高 token 效率以及在不同 token 预算约束下的推理灵活性。为了实现这一目标,我们将完整的思维过程截断,以适应从先验分布中采样的 token 预算,并促使模型为每次截断的思维总结出最优答案进行验证。这在推理过程中引入了可验证的密集奖励,有助于在强化学习优化中进行更有效的信用分配。然后,我们以解耦的方式优化思维策略和总结策略,以最大化累积奖励。此外,我们引入了一种新颖的方差缩减技术——预算相对策略优化(BRPO),以增强在强化思维策略时的学习过程的鲁棒性和效率。数学推理任务中的实验结果表明,我们的方法在各种先验分布下的所有思维预算下持续优于 GRPO,提升了训练和 token 效率。
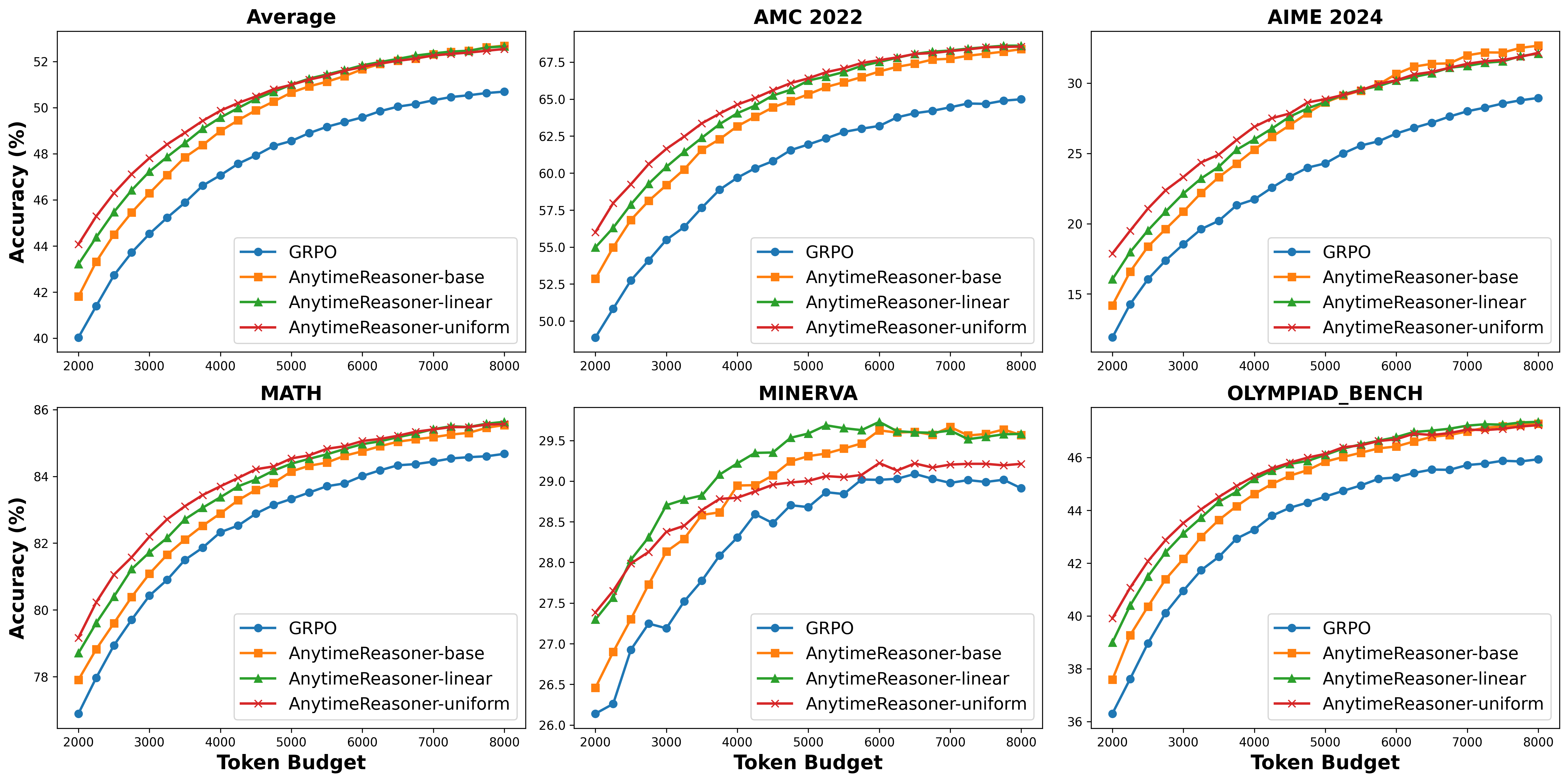

相比 GRPO,测试时伸缩性更好!