AI论文精选
每日论文
◀
06月16日
▶
⏶
53
反馈摩擦:LLMs 难以充分吸收外部反馈
⏶
37
有效红队测试策略遵守型智能体
⏶
36
扩散对偶性
⏶
32
通过跨模态注意力注入对齐的新视角图像与几何合成
⏶
22
LiveCodeBench Pro: 奥林匹克奖牌得主如何在竞技编程中评判大型语言模型?
⏶
22
ViCrit:一个用于视觉语言模型(VLM)中视觉感知的可验证强化学习代理任务
⏶
20
超越同质注意力:通过傅里叶近似的KV缓存实现内存高效的LLM
⏶
16
Med-PRM:一种带有逐步、指南验证过程奖励的医疗推理模型
⏶
14
SwS:强化学习中用于LLM推理的自我感知弱点驱动问题合成
⏶
10
DeepVideo-R1:通过难度感知回归式GRPO进行视频强化微调
⏶
10
JAFAR:在任何分辨率下提升任何特征
⏶
8
pLSTM:可并行化线性源转换标记网络
⏶
8
LoRA-Edit:通过掩码感知LoRA微调实现可控的首帧引导视频编辑
⏶
8
别理会
⏶
7
SkillBlender: 通过技能融合迈向多功能人形机器人全身运动与操作
⏶
7
针对交错图像-文本生成的高质量数据集和可靠评估
⏶
7
AbstentionBench:推理大型语言模型在无解问题上失败
⏶
6
密集检索器在简单查询上可能失效:揭示嵌入的粒度困境
⏶
6
一个利用TTS合成数据增强ASR的自精炼框架
⏶
6
学习一个持续思考令牌以增强测试时扩展性
⏶
5
解耦理解与引导式思维链推理的有害模因检测方法
⏶
5
Infinity Instruct:规模化指令选择与合成以增强语言模型
⏶
5
Mirage-1: 通过分层多模态技能增强和更新图形界面智能体
⏶
4
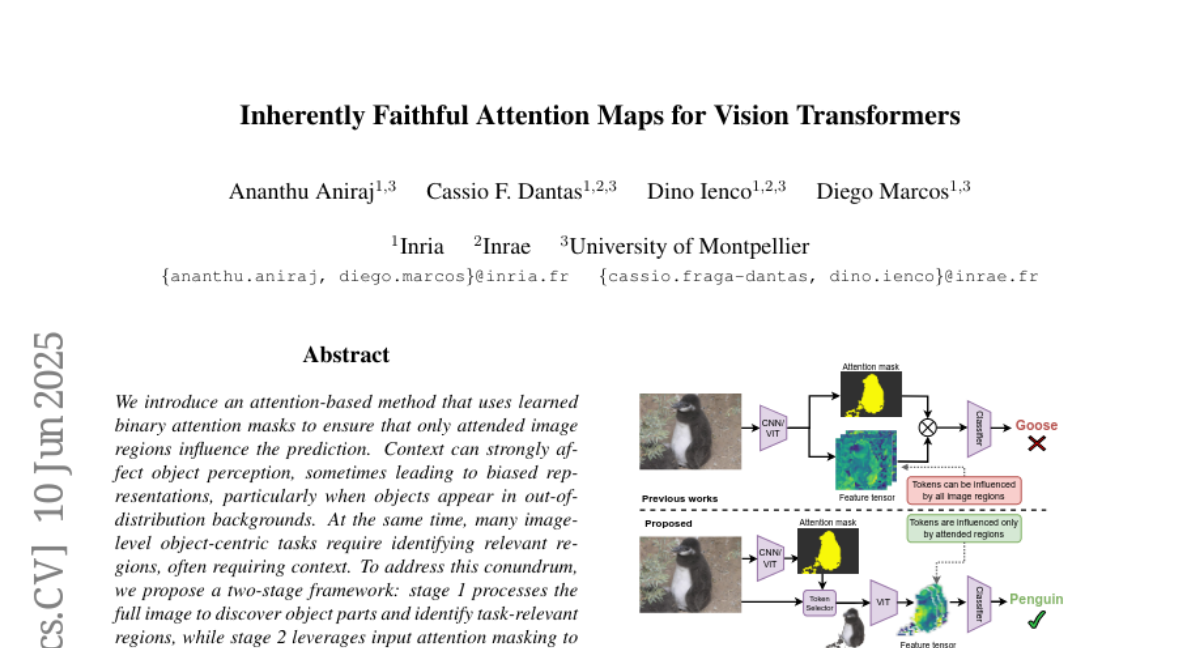
视觉Transformer的固有忠实注意力图
⏶
3
先提示候选,再蒸馏:一个用于LLM驱动数据标注的师生框架
⏶
3
奖励模型通过牺牲准确性换取吞吐量,从而实现可扩展的代码验证
⏶
2
基于评分标准引导的合成数据进行可配置的偏好微调