⏶31
EmbRACE-3K:复杂环境中的具身推理与行动
发表
由  Wei Huang 提交
Wei Huang 提交
Wei Huang 提交作者:  Mingxian Lin, Wei Huang, Yitang Li, Chengjie Jiang, Kui Wu, Fangwei Zhong, Shengju Qian, Xin Wang, Xiaojuan Qi
Mingxian Lin, Wei Huang, Yitang Li, Chengjie Jiang, Kui Wu, Fangwei Zhong, Shengju Qian, Xin Wang, Xiaojuan Qi
Mingxian Lin, Wei Huang, Yitang Li, Chengjie Jiang, Kui Wu, Fangwei Zhong, Shengju Qian, Xin Wang, Xiaojuan Qi摘要
近来,先进的视觉语言模型(VLM)在被动的、离线的图像和视频理解任务上展现出强大的性能。然而,在需要在线交互和主动场景理解的具身环境中,它们的有效性仍然有限。在此类场景中,智能体以第一人称视角感知环境,每一个动作都会动态地塑造后续的观察结果。即使是像 GPT-4o、Claude 3.5 Sonnet 和 Gemini 2.5 Pro 这样的顶级模型,在开放环境的交互中也表现不佳,在空间推理和长时程规划方面暴露出明显的局限性。为了弥合这一差距,我们推出了 EmRACE-3K 数据集,其中包含超过 3000 个语言指导的任务。这些任务设置在使用虚幻引擎(Unreal Engine)和 UnrealCV-Zoo 框架构建的多样化、照片般逼真的环境中。这些任务涵盖了广泛的具身挑战,包括导航、物体操控和多阶段目标执行。每个任务都以多步轨迹的形式展开,将第一人称视觉观察与高级指令、可执行的动作以及表达智能体每一步意图的自然语言理据配对。我们使用 EmRACE-3K 建立了一个基准,用于从三个关键维度评估 VLM 的具身推理能力:探索、动态空间语义推理和多阶段目标执行。在零样本设置下,所有模型的成功率均低于 20%,这凸显了我们基准所带来的挑战以及当前 VLM 在交互式环境中的局限性。为了展示 EmRACE-3K 的实用性,我们进一步通过监督学习和随后的强化学习对 Qwen2.5-VL-7B 进行了微调。这种方法在所有三个挑战类别中都取得了显著的改进,突显了该数据集在促进具身推理能力发展方面的有效性。

评论
Mingxian Lin论文作者
🚀 新数据集发布:EmbRACE-3K 🌍🧠
最近的视觉-语言模型(VLMs),如 GPT-4o、Claude 3.5 和 Gemini 2.5,在静态视觉任务中表现出色,但在闭环具身推理中却面临挑战,因为在该场景中,动作直接影响未来的观察。
我们推出了 EmbRACE-3K,一个包含超过 3,000 个多步骤、语言引导任务的数据集,这些任务设置在照片级真实的虚幻引擎环境中。
每个任务步骤包括:
👁️ 第一人称视角视觉观察
🗒️ 高级自然语言指令
🧭 已落地的动作
💬 分步自然语言推理理由
我们对三项核心推理技能进行了基准测试:
🧭 探索
🧠 动态空间语义推理
🎯 多阶段目标执行
领先的 VLM 零样本性能仍低于 20%,凸显了这项挑战。
通过监督学习和强化学习对 Qwen2.5-VL-7B 进行微调,在所有类别中均取得了持续提升。
📄 论文: arxiv.org/pdf/2507.10548
💻 代码: github.com/mxllc/EmbRACE-3K
🌐 项目页面: mxllc.github.io/EmbRACE-3K
🧠 让我们一起拓展具身智能的边界。

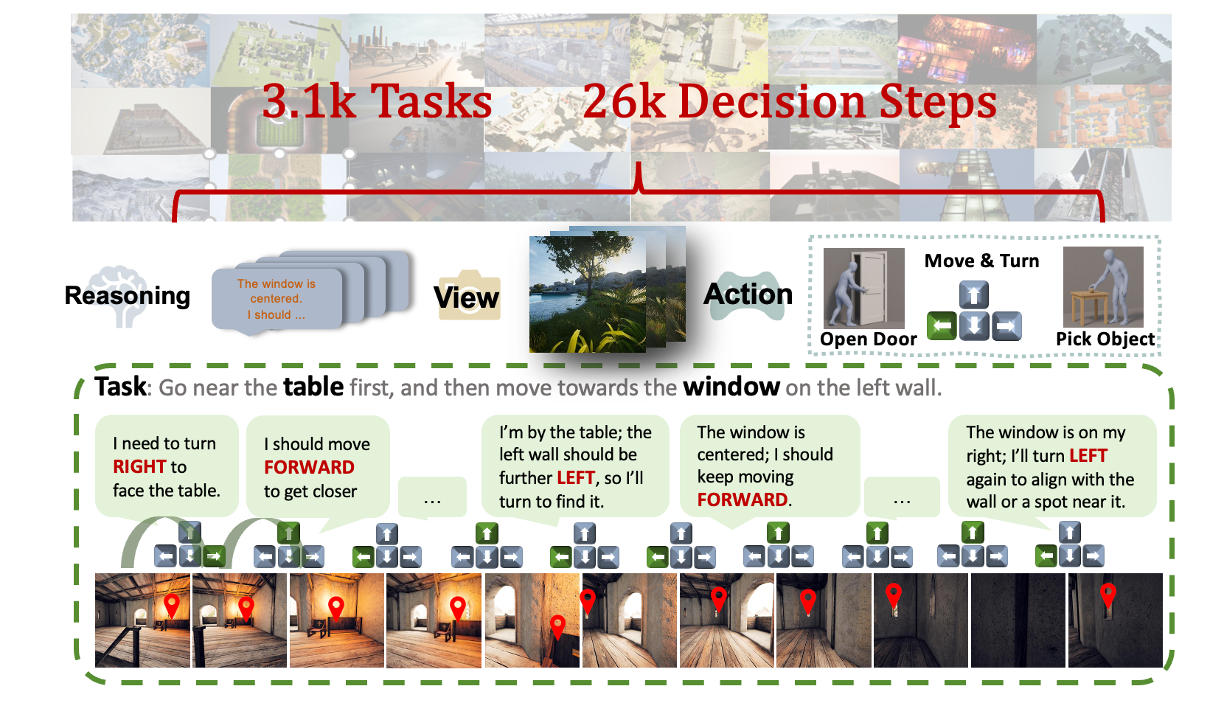
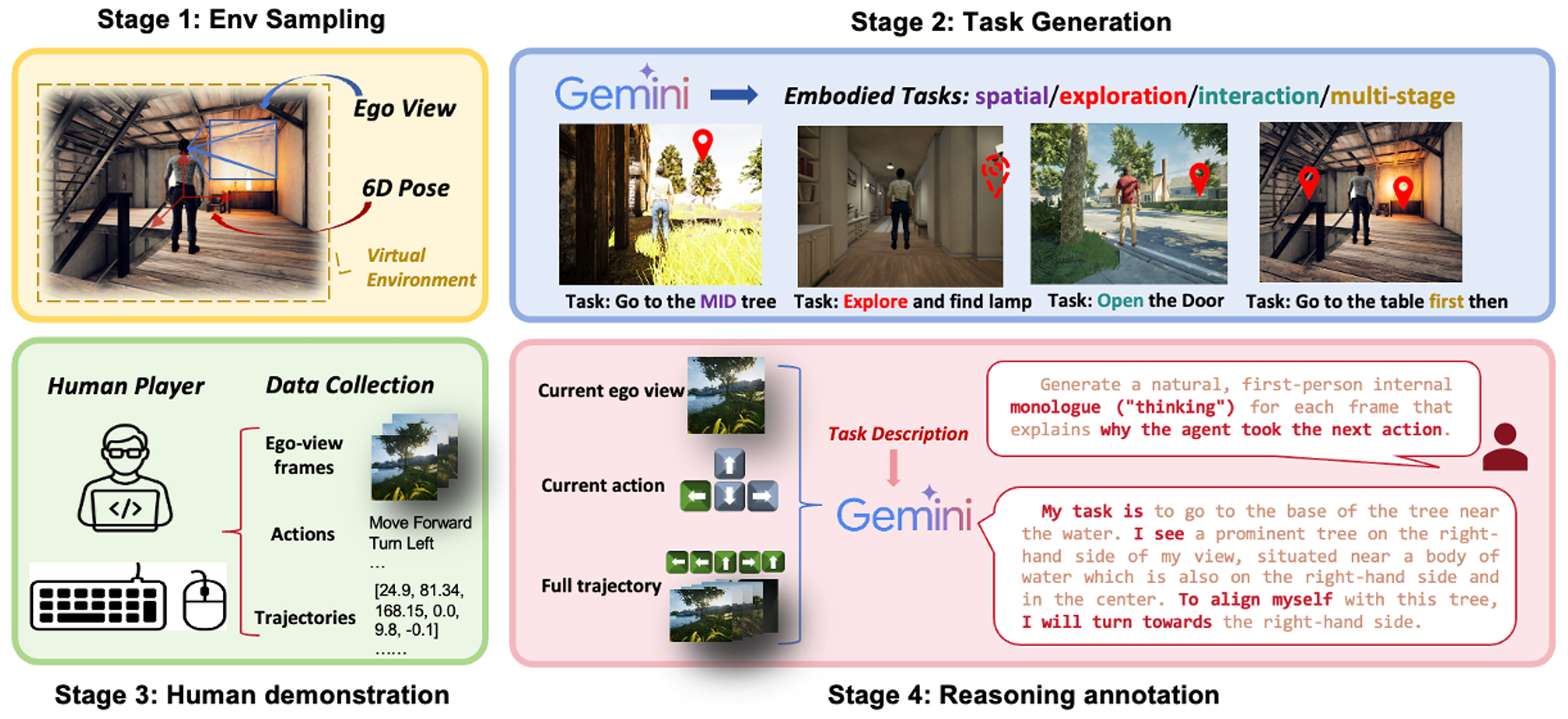
近期的视觉语言模型(VLM)在离线图像和视频理解方面表现出色,但它们在交互式、具身环境中的性能仍然有限。在闭环设置中,智能体以第一人称视角行动,每个决策都会改变未来的观测结果。即使是像 GPT-4o、Claude 3.5 Sonnet 和 Gemini 2.5 Pro 这样的领先模型,在空间推理和长远规划方面也面临挑战。我们推出了 EmbRACE-3K,这是一个包含超过 3,000 个语言引导任务的数据集,这些任务设置在多样化的虚幻引擎(Unreal Engine)环境中。每个任务都包含多个步骤,具有自我中心视角、高级指令、具身行动和自然语言解释。我们针对 VLM 的三项核心技能进行了基准测试:探索、动态空间语义推理和多阶段目标执行。在零样本测试中,所有模型的成功率都低于 20%,显示出明显的改进空间。通过监督学习和强化学习对 Qwen2.5-VL-7B 进行微调,在所有任务类型上都取得了一致的性能提升,这证明了 EmbRACE-3K 在发展具身智能方面的价值。