⏶21
多领域偏好可解释性
发表
由  Nitay Calderon 提交
Nitay Calderon 提交
Nitay Calderon 提交作者: Nitay Calderon, Liat Ein-Dor, Roi Reichart
摘要
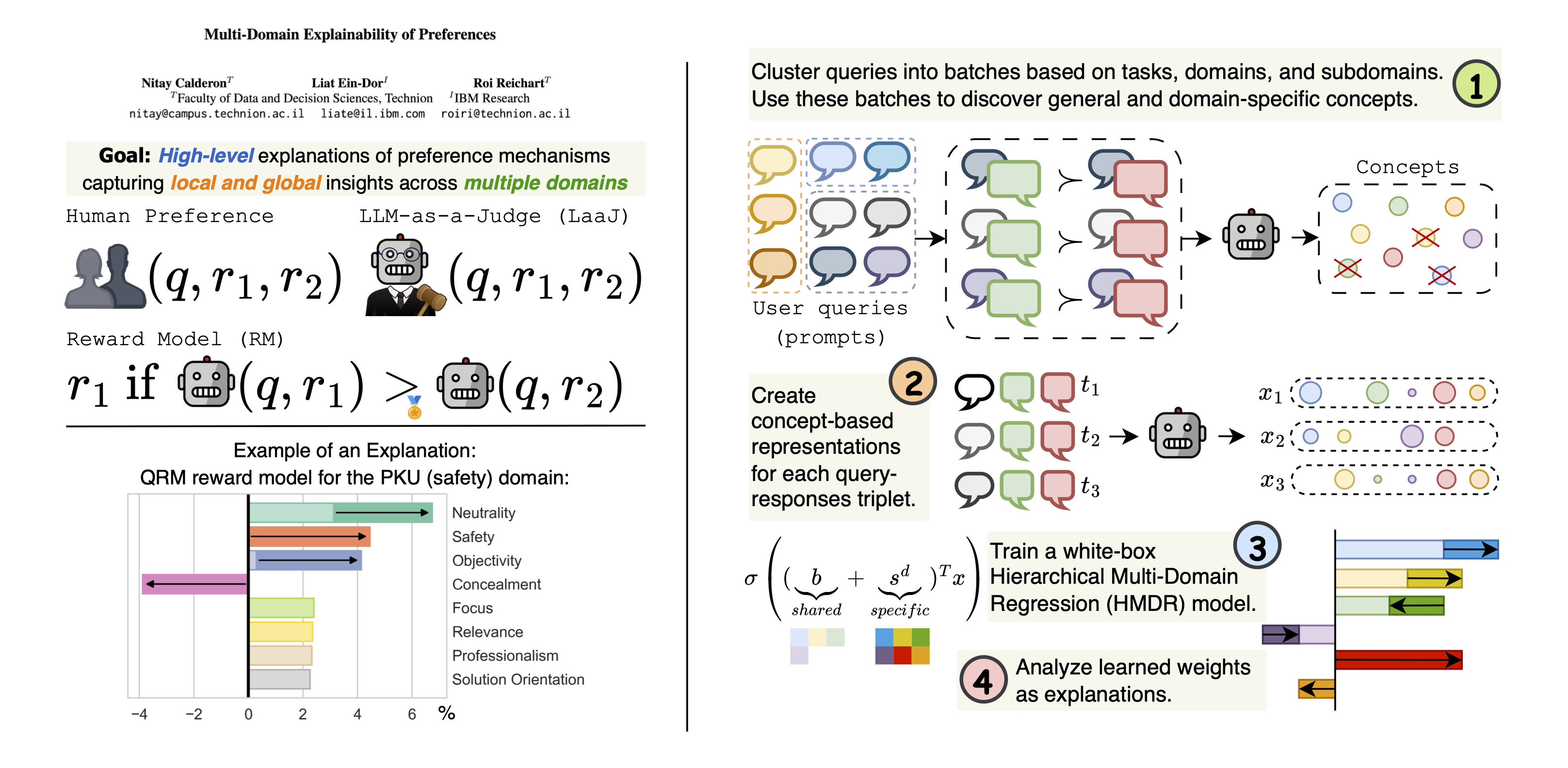
偏好机制,例如人类偏好、LLM 充当评审(LaaJ)以及奖励模型,对于对齐和评估大型语言模型(LLM)至关重要。然而,驱动这些偏好的底层概念仍未得到充分理解。在这项工作中,我们提出了一种全自动方法,用于生成跨多个领域的、基于概念的局部和全局偏好解释。我们的方法利用 LLM 来识别区分被选择和被拒绝响应的概念,并使用基于概念的向量来表示它们。为了模拟概念和偏好之间的关系,我们提出了一个白盒分层多领域回归模型,该模型捕获领域通用和领域特定的效应。为了评估我们的方法,我们精选了一个涵盖八个具有挑战性且多样化领域的数据库,并解释了十二种机制。我们的方法实现了强大的偏好预测性能,优于基线模型,同时具有可解释性。此外,我们在两种应用驱动的场景中评估了解释。首先,利用 LaaJ 解释中的概念指导 LLM 输出,可以产生那些评审一致偏好的响应。其次,用解释人类偏好的概念提示 LaaJ 可以提高其偏好预测。总而言之,我们的工作为 LLM 时代的可解释性建立了一个新范式。
https://arxiv.org/abs/2505.20088