⏶14
RLVR-World: 利用强化学习训练世界模型
发表
由  Jialong Wu 提交
Jialong Wu 提交
Jialong Wu 提交作者: Jialong Wu, Shaofeng Yin, Ningya Feng, Mingsheng Long
Jialong Wu, Shaofeng Yin, Ningya Feng, Mingsheng Long摘要
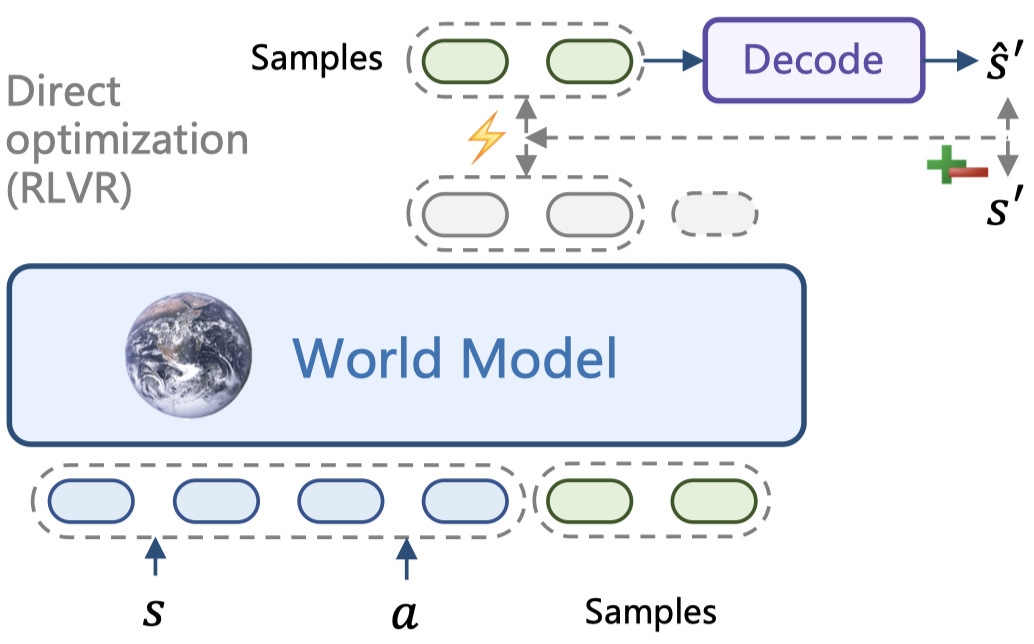
世界模型预测状态转移以响应动作,并且在各种模态中得到了越来越多的发展。然而,诸如最大似然估计(MLE)之类的标准训练目标通常与世界模型的任务特定目标(即预测准确性或感知质量等转移预测指标)不一致。在本文中,我们提出了 RLVR-World,一个利用可验证奖励强化学习(RLVR)直接优化世界模型以达到这些指标的统一框架。尽管将世界建模表述为 token 化序列的自回归预测,但 RLVR-World 将解码预测的指标评估为可验证奖励。我们在文本游戏、网页导航和机器人操作等领域的基于语言和基于视频的世界模型上展示了显著的性能提升。我们的工作表明,除了推理语言模型的最新进展外,RLVR 为更广泛地增强生成模型的效用提供了一种有前景的后期训练范式。
通用视觉定位