AI论文精选
强化学习 (RL)
⏶
381
DeepSeek-R1:通过强化学习激励LLM的推理能力
⏶
121
Kimi-VL 技术报告
⏶
117
DAPO:大规模开源LLM强化学习系统
⏶
102
TTRL:测试时强化学习
⏶
80
学习在离策略指导下进行推理
⏶
78
AdaptThink:推理模型可以学习何时思考
⏶
64
SynLogic:大规模合成可验证推理数据,迈向逻辑推理及其他领域
⏶
64
攀登凿刻的智慧比山顶更深邃:关于学习推理中的嘈杂奖励
⏶
52
Tina:通过 LoRA 实现的微小推理模型
⏶
43
ToolRL:奖励是工具学习的全部需求
⏶
41
T2I-R1:协同语义级和词元级CoT强化图像生成
⏶
39
Phi-4-Mini-Reasoning:探索小型推理语言模型在数学领域的极限
⏶
35
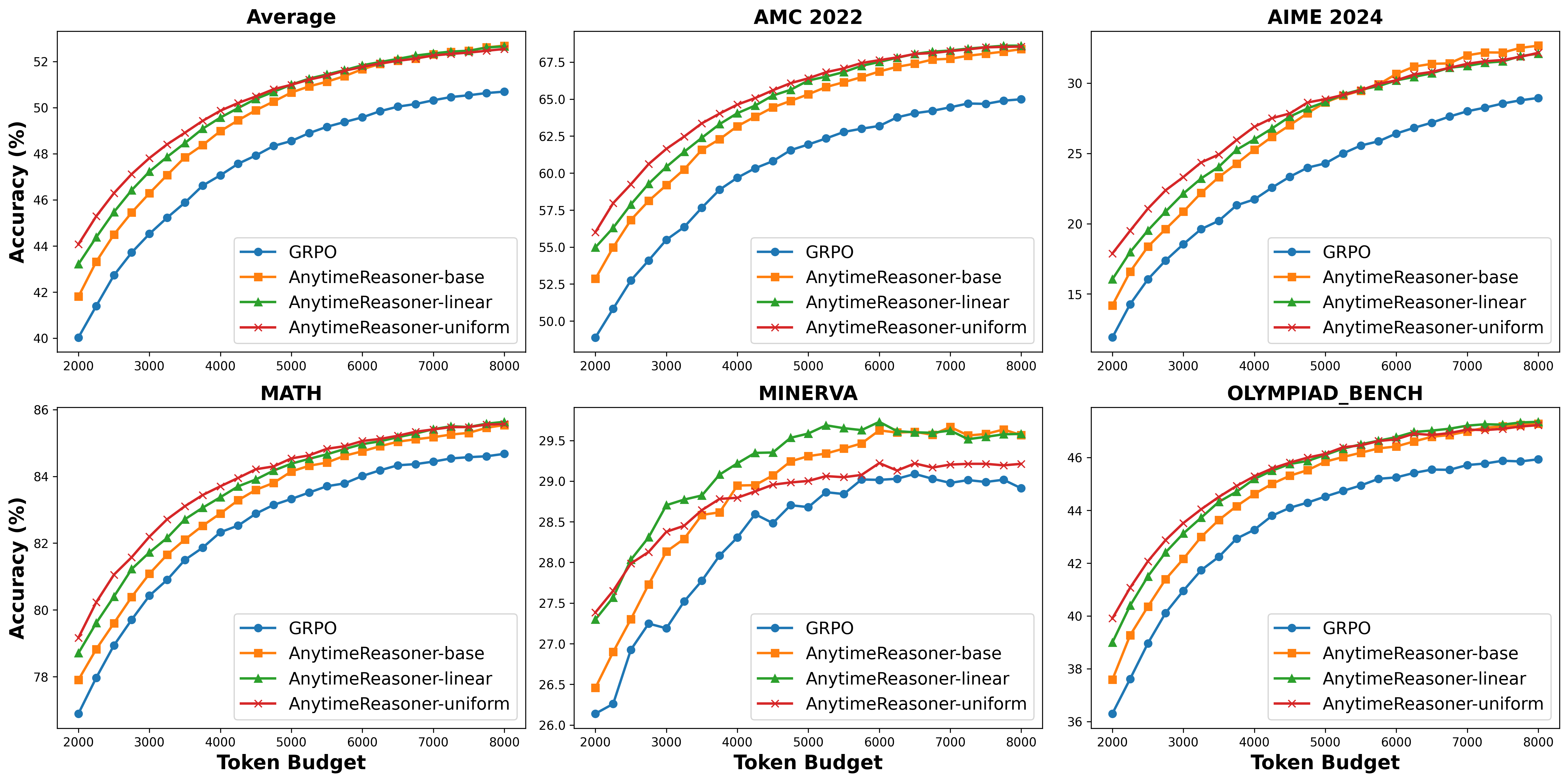
基于预算相对策略优化的随时推理优化
⏶
33
OTC:基于强化学习的最优工具调用
⏶
31
VLM-R1:稳定且可泛化的R1风格大型视觉语言模型
⏶
30
REFINE-AF:一个通过使用来自自动化反馈的强化学习自生成指令来对齐语言模型的任务无关框架
⏶
28
SFT 或 RL? 训练类似 R1 的推理大型视觉-语言模型的早期研究
⏶
26
SQL-R1:通过强化学习训练自然语言到SQL的推理模型
⏶
23
R1-Reward:通过稳定强化学习训练多模态奖励模型
⏶
21
对语言模型推理进展的冷静审视:陷阱与通往可重复性的路径
⏶
20
大型语言模型是贪婪的智能体:强化学习微调对决策能力的影响
⏶
19
DUMP:基于RL的LLM后训练的自动化分布级别课程学习
⏶
19
NoisyRollout:通过数据增强强化视觉推理
⏶
17
s3: 通过强化学习训练一个搜索智能体,你不需要那么多数据
⏶
15
激励大型语言模型实现高级指令遵循的推理
⏶
14
LLM推理的极简主义方法:从拒绝采样到强化学习
⏶
14
ReZero:通过再试一次增强LLM搜索能力
⏶
13
工程领域的LLMs:教会模型设计高性能火箭
⏶
11
思考还是不思考?通过强化学习实现视觉-语言模型的选择性推理
⏶
10
Thinker:学习快思慢想
⏶
9
RAGEN:通过多轮强化学习理解大型语言模型智能体中的自我演化
⏶
6
超越马尔可夫性:通过贝叶斯自适应强化学习实现大型语言模型的反思性探索推理
⏶
5
通过强化学习的混合潜在推理
⏶
5
R1-Searcher++:通过强化学习激励大型语言模型(LLMs)的动态知识获取
⏶
4
RL Tango:协同增强生成器和验证器用于语言推理
⏶
4
在数学推理中衔接监督学习与强化学习
⏶
2
CaRL: 使用简单的奖励学习可扩展的规划策略