AI论文精选
大型语言模型 (LLMs)
⏶
164
QeRL:超越效率——面向大型语言模型的量化增强强化学习
⏶
120
TTRL:测试时强化学习
⏶
118
超越Pass@1:变分问题合成的自我对弈能够维持RLVR
⏶
110
Hogwild! 推理:通过并发注意力实现并行LLM生成
⏶
104
ScienceBoard:评测多模态自主智能体在真实科学工作流程中
⏶
71
利用元学习进行系统提示优化
⏶
70
R2R:利用大小模型令牌路由高效探索分支推理路径
⏶
67
SynLogic:大规模合成可验证推理数据,迈向逻辑推理及其他领域
⏶
66
攀登凿刻的智慧比山顶更深邃:关于学习推理中的嘈杂奖励
⏶
64
带有测试时扩散的深度研究员
⏶
61
C3PO:用于测试时专家重混合的关键层、核心专家、协作路径优化
⏶
54
DeepCritic:使用大型语言模型进行审慎批判
⏶
52
具身智能体遇见个性化:探索记忆利用实现个性化辅助
⏶
48
CMPhysBench:用于评估凝聚态物理领域大语言模型的基准测试
⏶
47
VCR-Bench:视频链式思考推理的综合评估框架
⏶
46
PATS: 过程级自适应思维模式切换
⏶
45
利用不确定性:用于长周期 LLM 代理的熵调制策略梯度
⏶
39
BrowseComp-Plus:一个更公平、更透明的深度研究代理评估基准
⏶
36
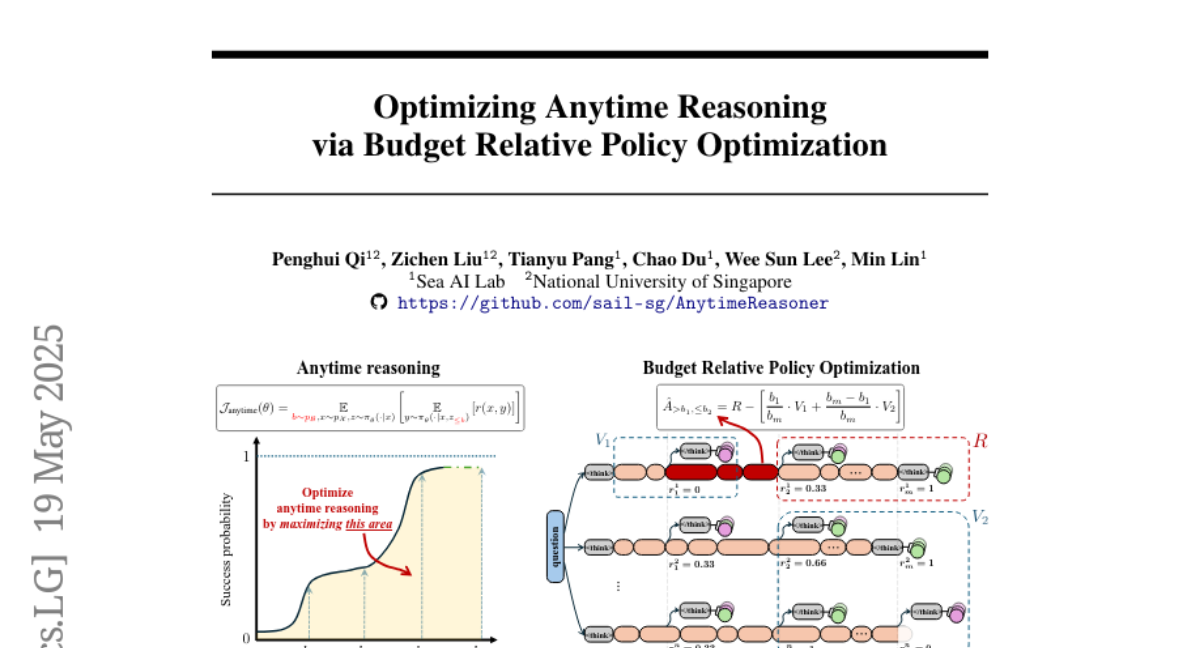
基于预算相对策略优化的随时推理优化
⏶
33
VLM-R1:稳定且可泛化的R1风格大型视觉语言模型
⏶
33
单流策略优化
⏶
31
何时集成:识别用于稳定和快速 LLM 集成的令牌级点
⏶
29
集体思维:多个并发推理智能体在令牌级粒度上协作
⏶
28
LoftQ:用于大型语言模型的LoRA微调感知量化
⏶
28
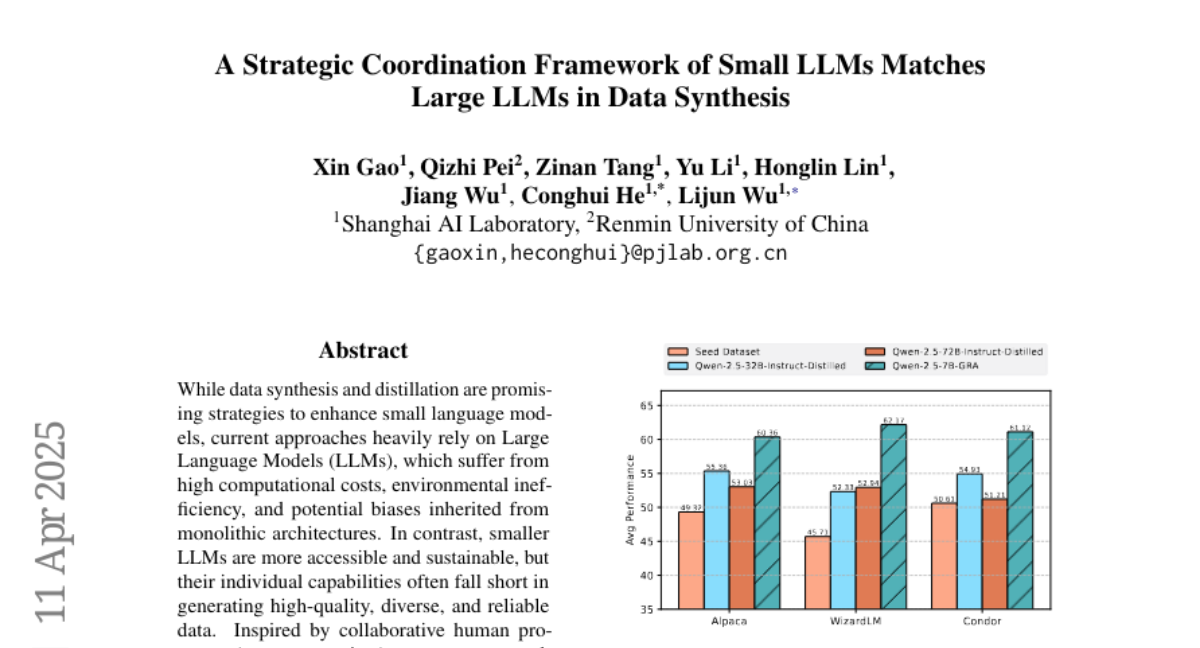
小型LLM在数据合成中的战略协调框架与大型LLM相匹配
⏶
27
黑暗中探索:基于测试时实例级策略梯度在潜在空间中的推理
⏶
25
AlayaDB:高效且有效的长上下文LLM推理的数据基础
⏶
25
通过监督学习框架实现 RLVR 的隐式 Actor-Critic 耦合
⏶
24
MetaMind:使用元认知多智能体系统建模人类社会思维
⏶
24
HANRAG:用于多跳问答的启发式精确抗噪检索增强生成
⏶
23
反应式 Transformer (RxT) -- 用于事件驱动的反应式语言的状态实时处理
⏶
22
ViCrit:一个用于视觉语言模型(VLM)中视觉感知的可验证强化学习代理任务
⏶
20
WALL-E 2.0:通过神经符号学习进行世界对齐改进基于世界模型的大型语言模型智能体
⏶
20
小型语言模型是代理 AI 的未来
⏶
20
PersonaFeedback:一个大规模人工标注的个性化基准
⏶
20
稳定知识,促进推理:用于RLVR的双令牌约束
⏶
19
HybriMoE:用于高效MoE推理的混合CPU-GPU调度和缓存管理
⏶
19
SEED-GRPO: 语义熵增强的 GRPO 用于不确定性感知的策略优化
⏶
19
StructEval:评估 LLMs 生成结构化输出能力的基准
⏶
18
s3: 通过强化学习训练一个搜索智能体,你不需要那么多数据
⏶
18
Muon 在尾部关联记忆学习中表现优于 Adam
⏶
17
从人类反馈中进行纳什学习
⏶
16
哪些数据属性激发了数学和代码推理?一项通过影响函数的研究
⏶
15
睡眠时间计算:超越测试时推理扩展
⏶
15
健康的LLM?对LLM了解英国政府公共卫生信息的基准测试
⏶
15
对先验的深思:大型语言模型在知识图谱上的可信推理
⏶
15
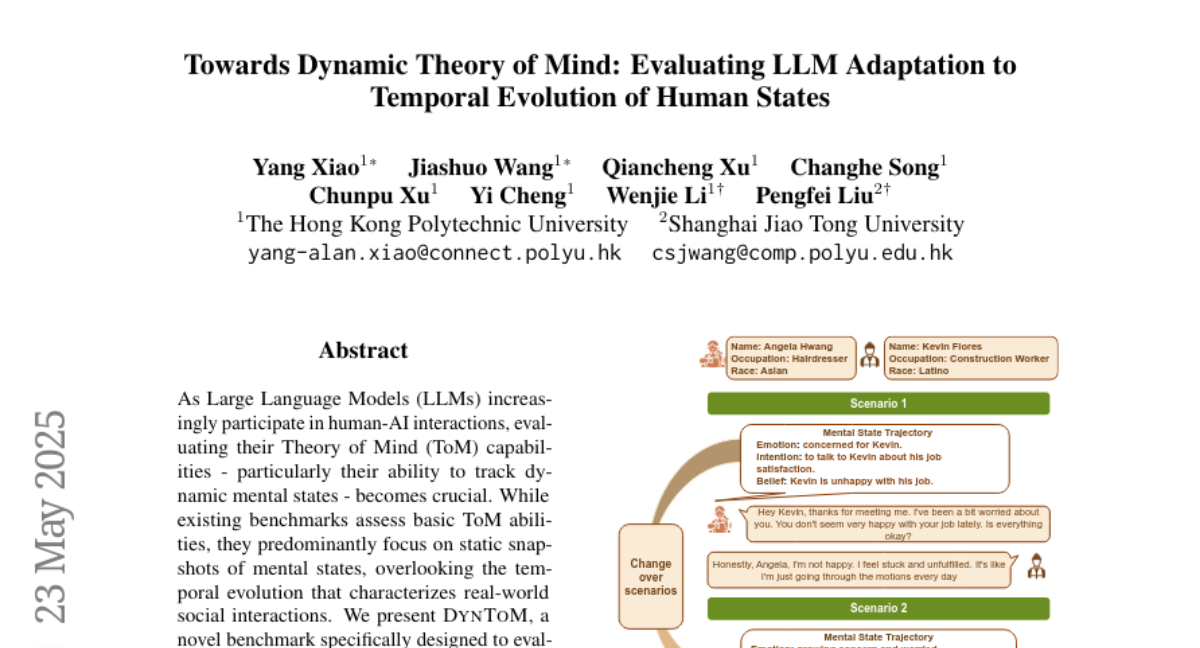
迈向动态心智理论:评估 LLM 对人类状态时间演变的适应性
⏶
15
MiCRo:用于个性化偏好学习的混合建模与上下文感知路由
⏶
14
大型语言模型中复杂推理的生成式评估
⏶
14
解耦全局-局部对齐用于提升组合理解
⏶
14
大型语言模型中的个性化安全:一个基准与一种基于规划的智能体方法
⏶
14
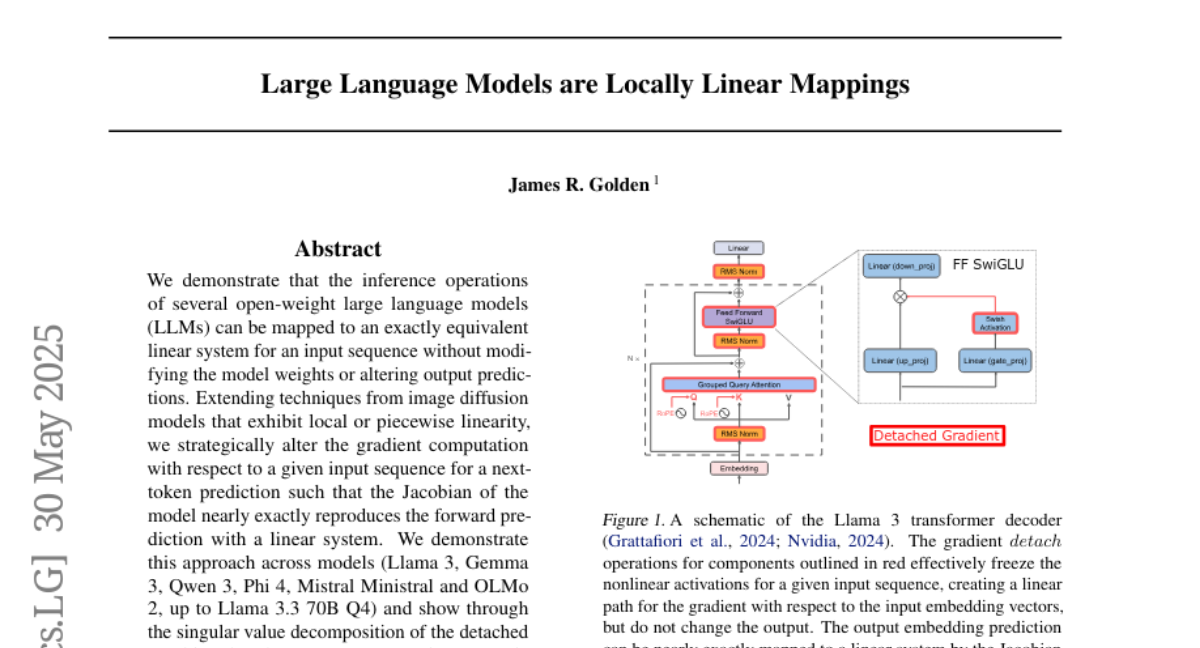
大语言模型是局部线性映射
⏶
13
X-Fusion: 引入新模态到冻结的大型语言模型
⏶
13
SlimMoE:通过专家精简和蒸馏对大型MoE模型进行结构化压缩
⏶
13
Sculptor: 通过主动上下文管理赋予LLM认知代理能力
⏶
11
LettinGo:探索推荐系统中的用户画像生成
⏶
11
及时行事事半功倍:语言模型的积极自我完善
⏶
11
使用 NVFP4 预训练大型语言模型
⏶
10
截断式近端策略优化
⏶
10
ZeCO: 零通信开销的线性注意力序列并行
⏶
9
TIME:一个用于大型语言模型在现实世界场景中进行时间推理的多层级基准
⏶
9
ExpertLongBench:通过结构化核对表评估语言模型在专家级长篇生成任务上的表现
⏶
9
ReCode:基于强化学习更新代码API知识
⏶
9
引导式解码及其在检索增强生成中的关键作用
⏶
8
强化微调的幻觉代价
⏶
8
AGENTIF:在智能体场景下评估大型语言模型遵循指令的能力
⏶
7
MedCaseReasoning: 从临床病例报告中评估和学习诊断推理
⏶
7
良好的开端是成功的一半:通过弱到强解码实现低资源偏好对齐
⏶
7
Turk-LettuceDetect: 土耳其 RAG 应用的幻觉检测模型
⏶
6
RainbowPlus:通过进化质量-多样性搜索增强对抗性提示生成
⏶
6
RL-PLUS:通过混合策略优化对抗LLM在强化学习中能力边界崩溃的问题
⏶
5
PROMPTEVALS:一个用于定制生产大语言模型管线的断言和护栏数据集
⏶
5
对计算高效测试时扩展的最优验证粒度的再思考
⏶
5
RL Tango:协同增强生成器和验证器用于语言推理
⏶
5
R1-Searcher++:通过强化学习激励大型语言模型(LLMs)的动态知识获取
⏶
5
通过半非负矩阵分解将MLP激活分解为可解释特征
⏶
5
TPTT:将预训练Transformer改造为巨擘
⏶
5
Reasoning Core: 用于 LLM 符号推理的可扩展 RL 环境
⏶
5
直接多令牌解码
⏶
4
ChiseLLM:释放推理大语言模型的强大力量,助力Chisel敏捷硬件开发
⏶
4
DLP:大型语言模型中的动态逐层剪枝
⏶
4
解耦理解与引导式思维链推理的有害模因检测方法
⏶
4
用于联合生成式搜索和推荐的语义 ID
⏶
4
剖析工具集成推理:一项实证研究与分析
⏶
4
CAT:因果注意力调优,用于将细粒度的因果知识注入大型语言模型
⏶
3
文档引用归属:使用大型语言模型研究引用关系
⏶
3
HelpSteer3-Preference:跨不同任务和语言的开放人工标注偏好数据
⏶
3
扩展和增强基于 LLM 的 AVSR:稀疏投影器混合方法
⏶
3
保持安全! 对大语言模型在问答中应对间接攻击时的安全策略保持情况进行基准测试
⏶
3
并非所有模型都适合专家卸载:论专家混合模型的局部路由一致性
⏶
3
EquivPruner:通过动作剪枝提升基于LLM的搜索的效率和质量
⏶
3
DFIR-Metric: 用于评估大型语言模型在数字取证和事件响应中表现的基准数据集
⏶
3
LLM能欺骗CLIP吗?通过文本更新基准测试预训练多模态表示的对抗性组合性
⏶
3
形式不确定性语法:自动化推理任务中何时信任大语言模型
⏶
3
GeometryZero: 通过群组对比策略优化改进大语言模型的几何解题能力
⏶
3
TeleMath:电信数学问题解决中大型语言模型基准
⏶
3
HeurAgenix:利用大型语言模型解决复杂组合优化挑战
⏶
3
DuaShepherd: 整合逐步正确性与潜在奖励以进行数学推理
⏶
3
混合推理:教导大型语言模型运用自适应策略进行推理
⏶
3
StyleBench: 评估大型语言模型中的思维风格
⏶
3
TENET:利用测试超越验证进行代码生成
⏶
3
Search-R3:统一大型语言模型中的推理和嵌入生成
⏶
2
LLM中的分词约束:符号和算术推理限制研究
⏶
2
MOLE: 使用大型语言模型提取和验证科学论文中的元数据
⏶
2
TAGS:一个具有检索增强推理和验证的测试时通用-专家框架