AI论文精选
扩散模型
⏶
174
LongLive:实时交互式长视频生成
⏶
142
NextStep-1:迈向具有连续标记的大规模自回归图像生成
⏶
88
Self-Forcing++:迈向分钟级高质量视频生成
⏶
70
扩展用于高分辨率图像合成的修正流Transformer
⏶
68
Story2Board:一种无需训练的富有表现力的故事板生成方法
⏶
64
OmniConsistency:从配对风格化数据中学习与风格无关的一致性
⏶
63
GPT-4o图像生成能力实证研究
⏶
63
OmniInsert: 通过扩散 Transformer 模型实现任何参考的无掩码视频插入
⏶
50
DreamID: 通过三元组身份群组学习实现高保真快速扩散模型换脸
⏶
49
VisualCloze:通过视觉上下文学习的通用图像生成框架
⏶
47
TAG: 幻觉抵抗扩散采样的切向放大引导
⏶
45
结合自回归 Transformer 和扩散模型与多引用自回归
⏶
42
反演与编辑:通过循环一致性模型实现高效快速的图像编辑
⏶
41
规模化图像和视频生成:通过测试时演化搜索
⏶
41
径向注意力:具有能量衰减的 O(nlog n) 稀疏注意力用于长视频生成
⏶
40
Tinker:扩散模型对3D的馈赠——无需逐场景优化,即可从稀疏输入进行多视图一致性编辑
⏶
39
倾听内在声音:通过中间特征反馈对齐 ControlNet 训练
⏶
36
RiemannLoRA: 用于无歧义 LoRA 优化的统一黎曼框架
⏶
35
I2VGen-XL:通过级联扩散模型实现高质量图像到视频合成
⏶
34
无需变分自编码器的潜在扩散模型
⏶
32
DanceGRPO:在视觉生成中释放 GRPO 的力量
⏶
30
ViDAR: 基于视频扩散感知的单目输入4D重建
⏶
30
InfGen:一种分辨率无关的可扩展图像合成范式
⏶
29
UMO:通过匹配奖励来扩展多身份一致性以实现图像定制
⏶
27
Cobra: 具有更广泛参考的高效线稿着色
⏶
27
StableAvatar:无限长音频驱动的虚拟形象视频生成
⏶
26
神经驱动图像编辑
⏶
25
通过注意力头选择实现细粒度扰动引导
⏶
25
Drax:通过离散流匹配进行语音识别
⏶
24
CogView3:通过中继扩散实现更精细更快速的文本到图像生成
⏶
24
DeepCache:免费加速扩散模型
⏶
24
采用对抗性后训练的快速文本到音频生成
⏶
24
利用扩散模型实现程序化图像编辑
⏶
23
通过动态令牌雕刻实现免训练的高效视频生成
⏶
22
帧引导:视频扩散模型中帧级控制的免训练引导
⏶
22
Mind-the-Glitch:用于检测主体驱动生成中不一致之处的视觉对应
⏶
21
通过正交微调控制文本到图像扩散
⏶
21
3D场景生成综述
⏶
21
CoDA:协调扩散噪声优化,用于铰接物体的全身操纵
⏶
21
迷失在潜在空间:潜在扩散模型在物理仿真中的实证研究
⏶
21
OBS-Diff: 扩散模型的一次性精确剪枝
⏶
21
PickStyle:利用上下文风格适配器进行视频到视频的风格迁移
⏶
19
对齐你的流:扩展连续时间流图蒸馏
⏶
19
HiWave:通过小波扩散采样实现免训练高分辨率图像生成
⏶
19
FreeMorph:利用扩散模型进行免调优的通用图像变形
⏶
19
DiffusionNFT: 正向过程的在线扩散强化
⏶
19
视觉自回归模型在推理时间扩展方面优于扩散模型
⏶
18
ZipIR:用于高分辨率图像复原的潜在金字塔扩散Transformer
⏶
18
MusicLDM:使用节拍同步混合策略增强文本到音乐生成的新颖性
⏶
18
基于自回归模型的个性化文本到图像生成
⏶
18
角色动画中的生成式 AI:技术、应用与未来方向的全面综述
⏶
17
MotionRAG:面向视频生成的运动检索增强图像
⏶
16
HoloTime: 驯服视频扩散模型用于全景 4D 场景生成
⏶
16
UNCAGE:文本到图像生成中掩码生成式 Transformer 的对比注意力引导
⏶
16
直接将完整的扩散轨迹与细粒度人类偏好对齐
⏶
16
InstructX:迈向量模型引导下的统一视觉编辑
⏶
15
UniGeo:控制视频扩散模型用于统一一致的几何估计
⏶
15
噪声超网络:摊销扩散模型中的测试时间计算
⏶
14
从反思到完善:通过反射调优扩展文本到图像扩散模型的推理时优化
⏶
14
DCM: 高效高质量视频生成的双专家一致性模型
⏶
13
归一化注意力引导:扩散模型的通用负向引导
⏶
12
NeRFiller:通过生成式3D图像修复完成场景
⏶
12
通过嵌入式表示预热进行高效生成模型训练
⏶
12
用于快速扩散采样的可微分求解器搜索
⏶
12
AnyI2V:通过运动控制将任意条件图像动画化
⏶
12
图像扩散模型中的局部性源于数据统计
⏶
11
D^2iT:用于精确图像生成的动态扩散Transformer
⏶
11
精准配色:融合感知色彩空间与文本嵌入,提升扩散生成质量
⏶
10
JAM:一个具有细粒度可控性和审美对齐的微型流式歌曲生成器
⏶
10
通过直接分组偏好优化强化扩散模型
⏶
9
EPiC:通过精准的锚定视频引导实现高效的视频摄像机控制学习
⏶
9
通过词法偏置的自回归图像水印:一种抵抗再生成攻击的方法
⏶
9
环境扩散 Omni:用坏数据训练好模型
⏶
9
面向指令引导图像编辑的视觉自回归建模
⏶
8
LoRA-Edit:通过掩码感知LoRA微调实现可控的首帧引导视频编辑
⏶
8
LAMIC:多模态扩散 Transformer 可扩展性驱动的布局感知多图像合成
⏶
7
3D-Fixup: 利用3D先验知识提升照片编辑
⏶
7
PrismLayers: 用于高质量多层透明图像生成模型的开放数据
⏶
7
DiffDecompose:通过扩散Transformer实现Alpha合成图像的逐层分解
⏶
7
利用可分解流匹配改进渐进式生成
⏶
7
DiffSpectra:利用扩散模型从光谱中解析分子结构
⏶
7
TC-LoRA:用于自适应扩散控制的按时间调制的条件 LoRA
⏶
6
几何可编辑且外观保持的物体合成
⏶
6
SpA2V: 利用空间听觉线索进行音频驱动的空间感知视频生成
⏶
6
StrandDesigner:通过草图引导实现实用链条生成
⏶
6
Bifrost-1:通过补丁级CLIP潜在特征连接多模态大型语言模型和扩散模型
⏶
6
离散噪声反演用于下一代自回归文本图像编辑
⏶
6
DC-Gen:通过深度压缩的潜在空间进行训练后扩散加速
⏶
6
LightCache:用于视频生成的内存高效、无需训练的加速器
⏶
5
掷骰子,三思而后行:超越下一个 token 预测的创造性限制
⏶
5
解耦身份,协同情感:关联感知的情感口播肖像生成
⏶
5
WorldGenBench:一个用于推理驱动的文本到图像生成的集成了世界知识的基准测试
⏶
5
VARD:利用基于价值的强化学习对扩散模型进行高效且密集微调
⏶
5
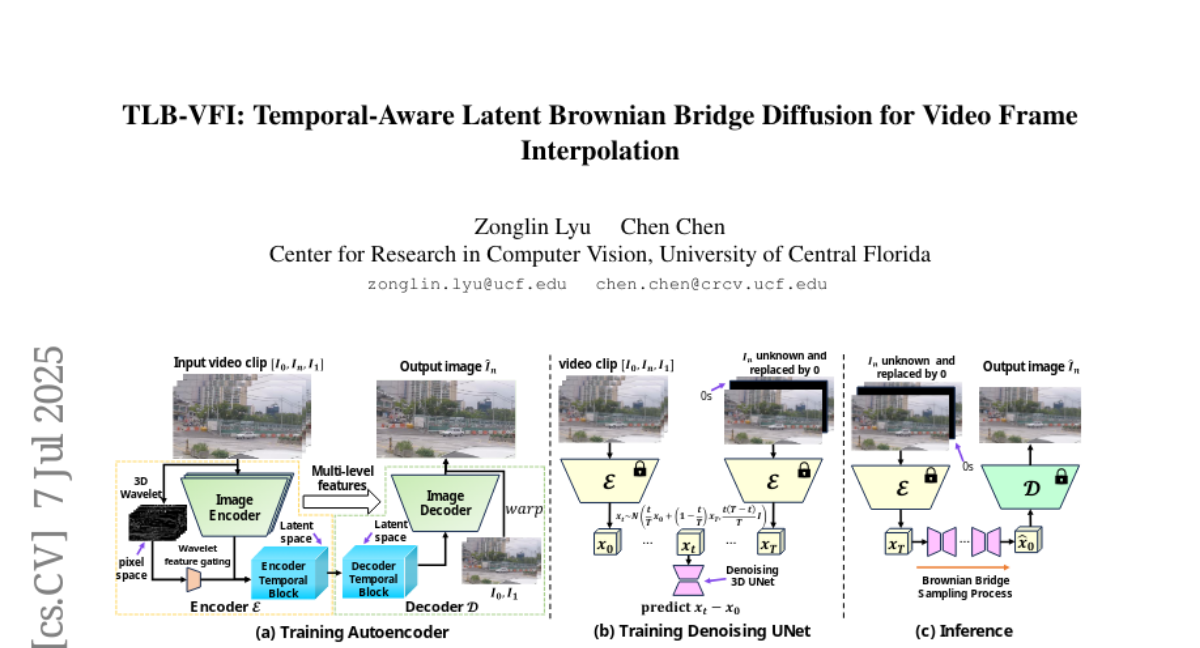
TLB-VFI: 时间感知潜在布朗桥扩散用于视频帧插值
⏶
5
FlashEdit:解耦速度、结构和语义以进行精确图像编辑
⏶
5
平衡匹配:基于隐式能量模型的生成建模
⏶
5
G^2RPO:用于流模型中精确奖励的粒度GRPO
⏶
4
使用强化学习训练扩散模型
⏶
4
用于高效3D LiDAR场景补全的直接偏好优化扩散蒸馏
⏶
4
ReMoMask:检索增强型掩蔽运动生成
⏶
4
SAEdit:通过稀疏自编码器对连续图像编辑进行令牌级别控制
⏶
3
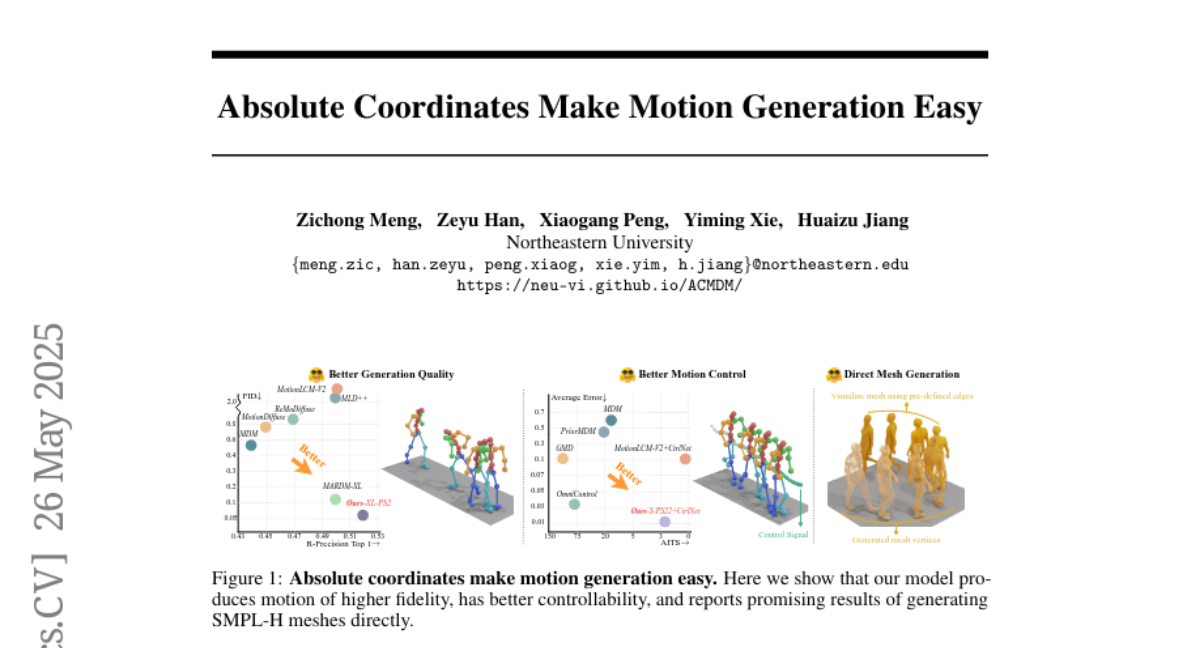
绝对坐标使运动生成变得容易
⏶
3
SridBench:图像生成模型科学研究插图绘制评测
⏶
3
审计与修复:文本到图像扩散模型中故事可视化一致性的代理框架
⏶
3
SpotEdit:视觉引导的图像编辑方法评估