AI论文精选
每日论文
◀
05月22日
▶
⏶
98
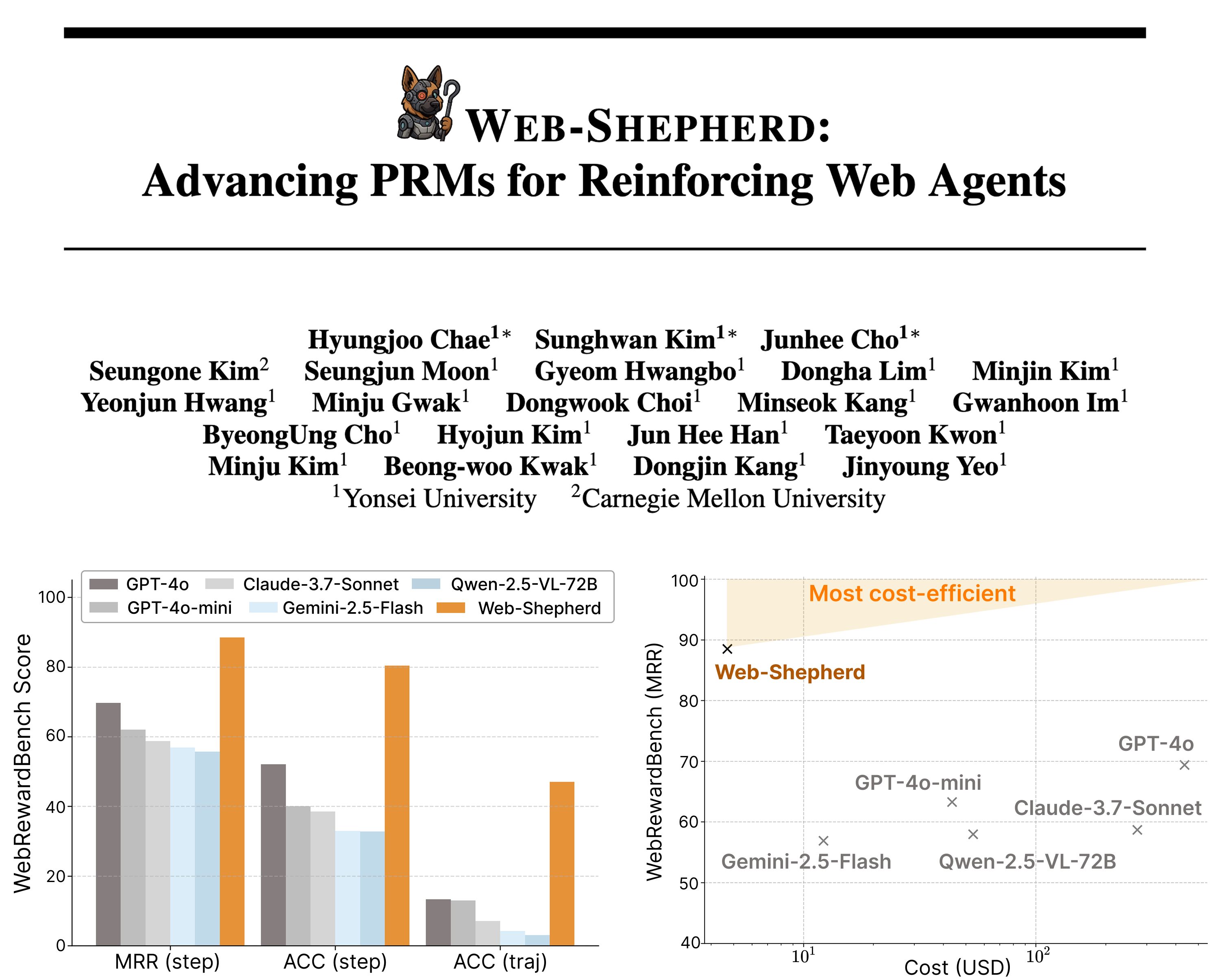
Web-Shepherd:推进 PRMs 以增强 Web Agents
⏶
85
MMaDA: 多模态大型扩散语言模型
⏶
72
量化感知训练的缩放定律
⏶
53
扩散模型 vs 自回归语言模型:文本嵌入视角
⏶
51
UniVG-R1: 结合强化学习的推理引导通用视觉定位
⏶
43
用于计算机操作的高效 Agent 训练
⏶
37
这次不同:时间序列基础模型的可观测性视角
⏶
32
利用基于长度的自适应奖励塑形学习高效推理
⏶
25
Vid2World: 将视频扩散模型构建为交互式世界模型
⏶
23
从单张图像构建 3D 小镇
⏶
22
何时继续思考:用于高效推理的自适应思维模式切换
⏶
20
lmgame-Bench:LLMs 玩游戏水平如何?
⏶
17
学习通过思维混合进行逻辑推理
⏶
17
VerifyBench:面向大型语言模型的基于参考的奖励系统的基准测试
⏶
16
dKV-Cache:扩散语言模型的缓存
⏶
15
对先验的深思:大型语言模型在知识图谱上的可信推理
⏶
15
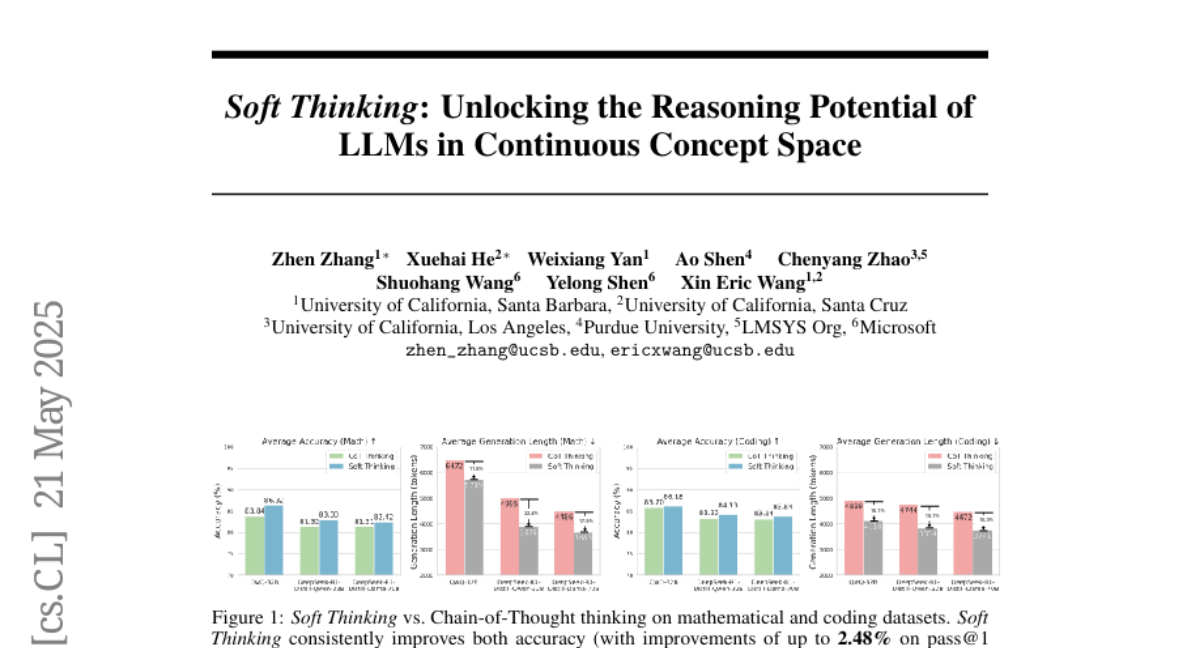
软思维:在连续概念空间中释放 LLM 的推理潜力
⏶
15
IA-T2I:互联网增强的文本到图像生成
⏶
14
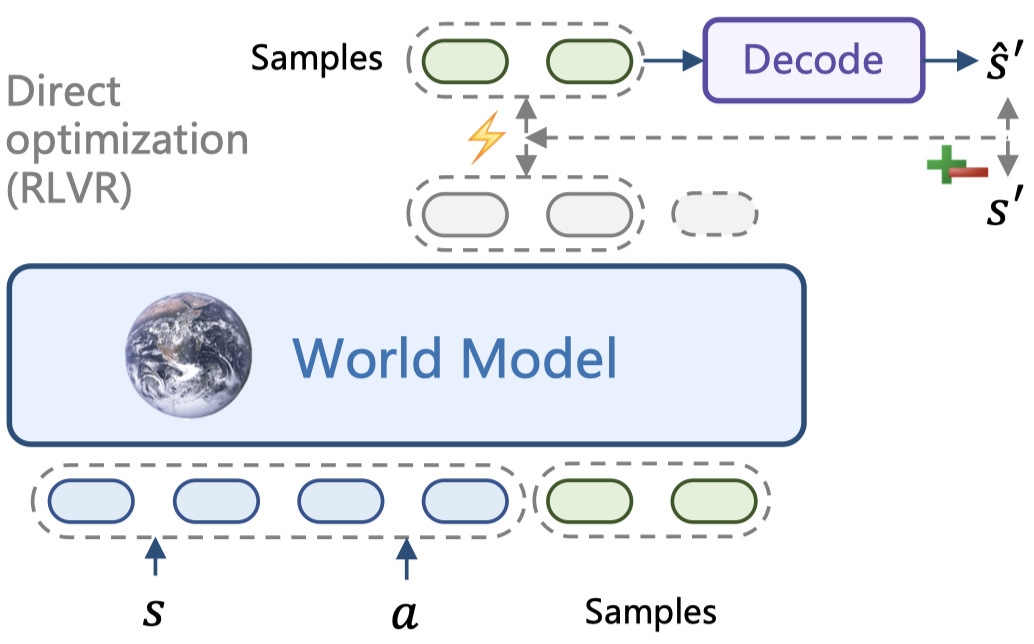
RLVR-World: 利用强化学习训练世界模型
⏶
14
在开源 LLM 上微调时要小心:你的微调数据可能被秘密窃取!
⏶
13
如何增强大型推理模型的安全性:一项实证研究
⏶
12
DiCo:重振卷积网络,实现可扩展和高效的扩散建模
⏶
11
BARREL:用于事实性和可靠 LRMs 的边界感知推理
⏶
10
文本生成:超越离散词元采样
⏶
10
ConvSearch-R1:通过强化学习结合推理,增强对话式搜索的查询重述
⏶
7
AutoMat:通过 Agent 工具使用实现基于显微镜数据的自动化晶体结构重建
⏶
7
无需手动测试集评估偏差:大型语言模型(LLMs)的概念表示视角
⏶
6
熵最小化在LLM推理中的不可思议的有效性
⏶
5
VARD:利用基于价值的强化学习对扩散模型进行高效且密集微调
⏶
5
用于强化微调的先验提示工程
⏶
5
音频越狱:一个用于越狱大型音频-语言模型的开放综合基准
⏶
5
BLEUBERI: BLEU 是一个令人惊讶地有效的指令遵循奖励
⏶
4
PiFlow:通过多 Agent 协作实现的原理感知科学发现
⏶
4
RL Tango:协同增强生成器和验证器用于语言推理
⏶
4
HumaniBench:一个以人为中心的用于大型多模态模型评测的框架
⏶
4
WebNovelBench:在网络小说分布上定位LLM小说家
⏶
4
BanditSpec: 基于多臂老虎机算法的适应性推测性解码
⏶
3
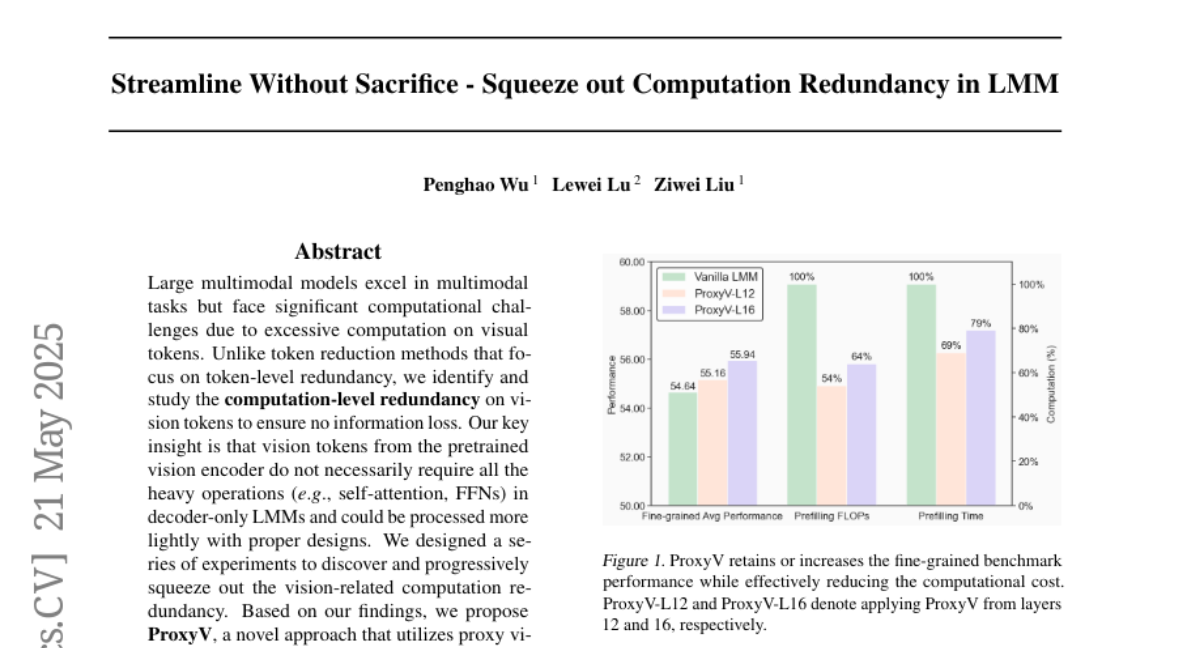
在不牺牲的前提下精简 - 消除LMM中的计算冗余
⏶
3
扩展和增强基于 LLM 的 AVSR:稀疏投影器混合方法
⏶
2
MultiHal:一个用于基于知识图谱评估LLM幻觉的多语言数据集
⏶
2
上下文学习通过对说话人和语言变体的类人适应提升语音识别
⏶
1
特定语言知识: 模型在 X 语言中知道得比英语更好吗?