⏶17
基于区域的聚类判别用于视觉表示学习
发表
由  xiangan 提交
xiangan 提交
xiangan 提交作者: Yin Xie,  Kaicheng Yang, Xiang An,
Kaicheng Yang, Xiang An,  Kun Wu, Yongle Zhao, Weimo Deng, Zimin Ran, Yumeng Wang, Ziyong Feng, Roy Miles, Ismail Elezi, Jiankang Deng
Kun Wu, Yongle Zhao, Weimo Deng, Zimin Ran, Yumeng Wang, Ziyong Feng, Roy Miles, Ismail Elezi, Jiankang Deng
Kaicheng Yang, Xiang An, Kun Wu, Yongle Zhao, Weimo Deng, Zimin Ran, Yumeng Wang, Ziyong Feng, Roy Miles, Ismail Elezi, Jiankang Deng摘要
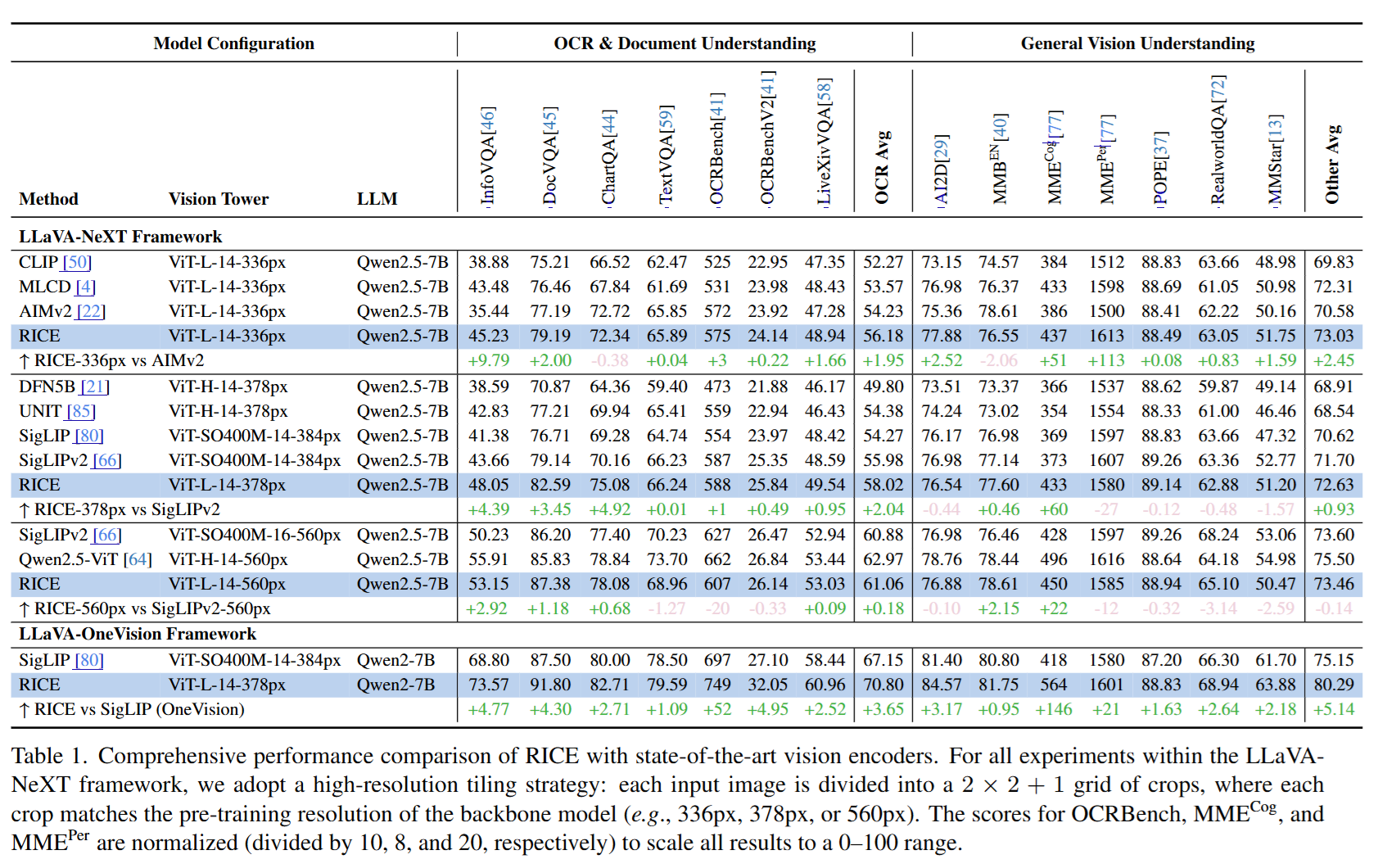
学习视觉表示是广泛下游任务的基础。尽管最近的视觉-语言对比模型,如CLIP和SigLIP,通过大规模视觉-语言对齐取得了令人印象深刻的零样本性能,但它们对全局表示的依赖限制了它们在密集预测任务(如定位、OCR和分割)中的有效性。为了弥补这一差距,我们引入了区域感知聚类判别(RICE),这是一种新颖的方法,旨在增强区域级视觉和OCR能力。我们首先构建了一个十亿级的候选区域数据集,并提出了一种区域Transformer层来提取丰富的区域语义。我们进一步设计了一种统一的区域聚类判别损失,它在单一分类框架内共同支持对象和OCR学习,从而实现大规模数据上的高效和可扩展分布式训练。大量实验表明,RICE在分割、密集检测以及多模态大型语言模型(MLLMs)的视觉感知等任务上始终优于现有方法。预训练模型已发布在https://github.com/deepglint/MVT。
评论
xiangan论文作者
论文提交者