⏶11
通过提升方法使旧SAE掌握新的领域技巧
发表
由  Nikita Balagansky 提交
Nikita Balagansky 提交
Nikita Balagansky 提交作者:  Nikita Koriagin, Yaroslav Aksenov,
Nikita Koriagin, Yaroslav Aksenov,  Daniil Laptev, Gleb Gerasimov, Nikita Balagansky,
Daniil Laptev, Gleb Gerasimov, Nikita Balagansky,  Daniil Gavrilov
Daniil Gavrilov
Nikita Koriagin, Yaroslav Aksenov, Daniil Laptev, Gleb Gerasimov, Nikita Balagansky, Daniil Gavrilov摘要
稀疏自编码器(SAE)已成为解释大语言模型(LLM)内部表示的强大工具,但它们往往无法捕获训练语料库中不常见的领域特定特征。本文引入了一种残差学习方法,旨在解决这种特征盲区,而无需进行完全的重新训练。我们提出训练一个次级SAE,专门用于建模预训练SAE在领域特定文本上的重建误差,从而有效地捕获主模型遗漏的特征。通过在推理过程中将两个模型的输出相加,我们证明在多个专业领域中,LLM交叉熵和解释方差指标均有显著改进。我们的实验表明,该方法能够有效地将新的领域知识整合到现有SAE中,同时保持其在通用任务上的性能。这种方法使研究人员能够有选择地增强SAE在特定感兴趣领域的可解释性,为LLM的目标化机械可解释性开辟了新的可能性。
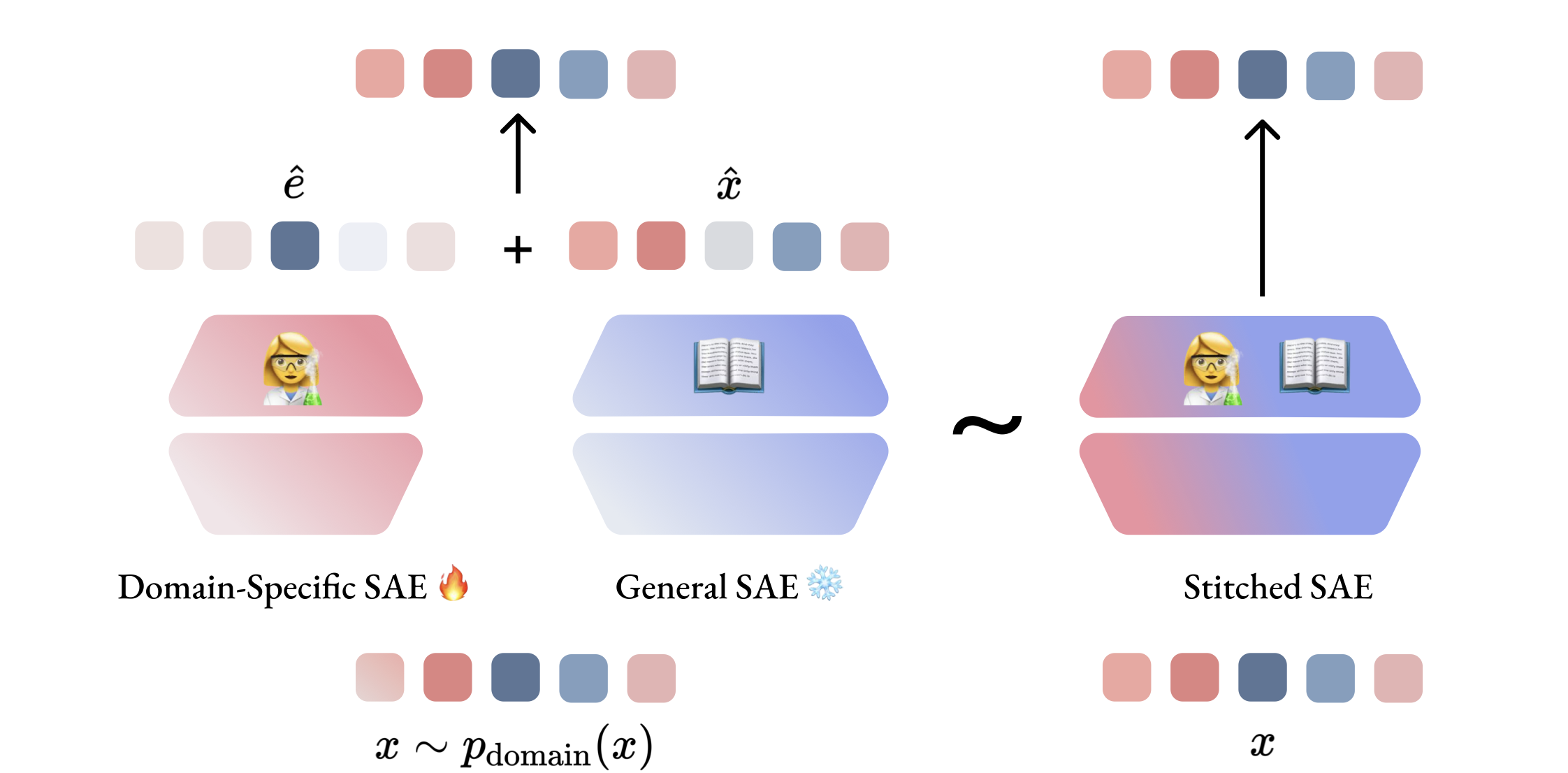
我们提出了一些方法,用于使SAE适应新的语言或领域,同时不遗忘之前获得的特征。我们相信这种方法将有助于SAE在实际应用中的适应。