⏶85
基于反射生成模型的测试时缩放
发表
由  Yuxin Wang 提交
Yuxin Wang 提交
Yuxin Wang 提交作者: Zixiao Wang, Yuxin Wang, Xiaorui Wang, Mengting Xing, Jie Gao,  Jianjun Xu, Guangcan Liu, Chenhui Jin, Zhuo Wang, Shengzhuo Zhang, Hongtao Xie
Jianjun Xu, Guangcan Liu, Chenhui Jin, Zhuo Wang, Shengzhuo Zhang, Hongtao Xie
Yuxin Wang, Xiaorui Wang, Mengting Xing, Jie Gao, Jianjun Xu, Guangcan Liu, Chenhui Jin, Zhuo Wang, Shengzhuo Zhang, Hongtao Xie摘要
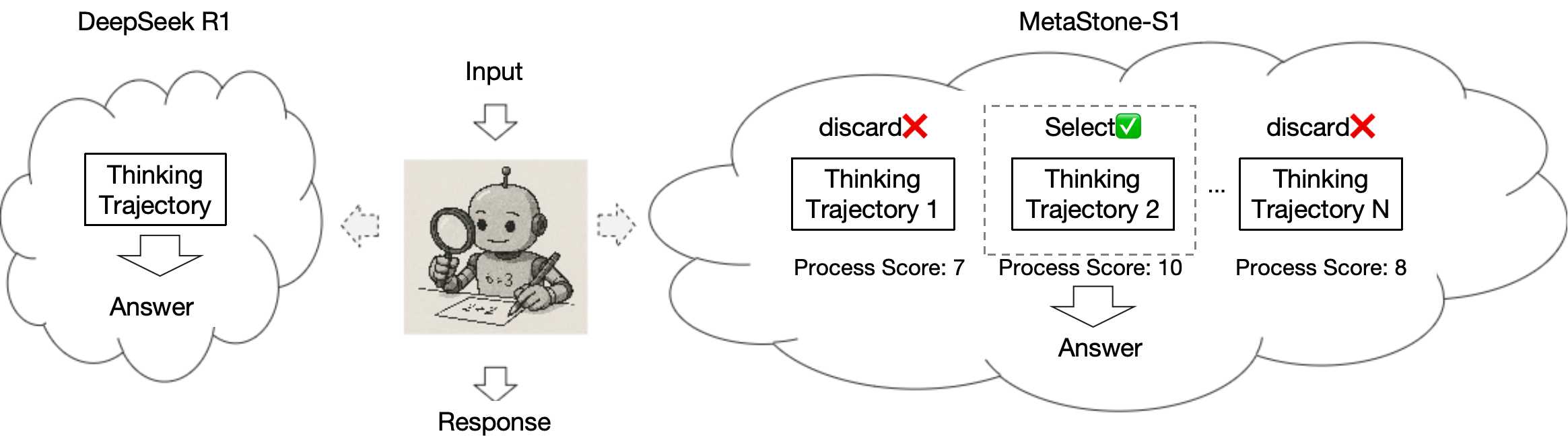
我们推出了首个反射生成模型MetaStone-S1,它通过自监督过程奖励模型(SPRM)获得了OpenAI o3的性能。通过共享骨干网络并分别使用特定任务头进行下一token预测和过程评分,SPRM成功将策略模型和过程奖励模型(PRM)集成到一个统一接口中,无需额外的过程标注,从而将PRM参数减少了99%以上,以实现高效推理。配备SPRM后,MetaStone-S1自然适用于测试时扩展(TTS),我们根据可控的思考长度提供了三种推理努力模式(低、中、高)。此外,我们通过实验建立了一个扩展定律,揭示了总思考计算量与TTS性能之间的关系。实验表明,我们的MetaStone-S1仅以32B的参数量就实现了与OpenAI-o3-mini系列相当的性能。为了支持研究社区,我们已在https://github.com/MetaStone-AI/MetaStone-S1开源了MetaStone-S1。
 MetaStone
MetaStone
我们推出了MetaStone-S1,这是一款开创性的反射生成模型,旨在通过新的反射生成形式显著增强测试时扩展(TTS)能力。这项工作提供了三项主要贡献:
反射生成形式:通过在策略模型和过程奖励模型(PRM)之间共享骨干网络,我们开发了一个统一的接口,高效地整合了推理和评估过程,仅引入了53M参数的PRM以实现高效推理。
自监督过程奖励模型:我们引入了一种新颖的自监督学习策略,能够动态地将结果奖励分配给各个推理步骤,而无需过程级别的标注。
扩展定律和“顿悟时刻”:我们通过经验证明了推理计算与TTS性能之间的扩展定律,并发现了反射生成形式的“顿悟时刻”(aha-moment)。在AIME24、AIME25、LiveCodeBench和C-EVAL等基准测试上的广泛评估表明,与更大的开源和闭源模型相比,MetaStone-S1始终保持最先进的性能。
为了促进社区驱动的研究,我们已经开源了MetaStone-S1。代码、模型和资源可在https://github.com/MetaStone-AI/MetaStone-S1获取。