⏶10
通过合成任务和强化学习教会大型语言模型保持上下文忠实性
发表
由  ssz 提交
ssz 提交
ssz 提交作者: Shuzheng Si,  Haozhe Zhao, Cheng Gao, Yuzhuo Bai, Zhitong Wang, Bofei Gao, Kangyang Luo, Wenhao Li, Yufei Huang, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, Maosong Sun
Haozhe Zhao, Cheng Gao, Yuzhuo Bai, Zhitong Wang, Bofei Gao, Kangyang Luo, Wenhao Li, Yufei Huang, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, Maosong Sun
Shuzheng Si, Haozhe Zhao, Cheng Gao, Yuzhuo Bai, Zhitong Wang, Bofei Gao, Kangyang Luo, Wenhao Li, Yufei Huang, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, Maosong Sun摘要
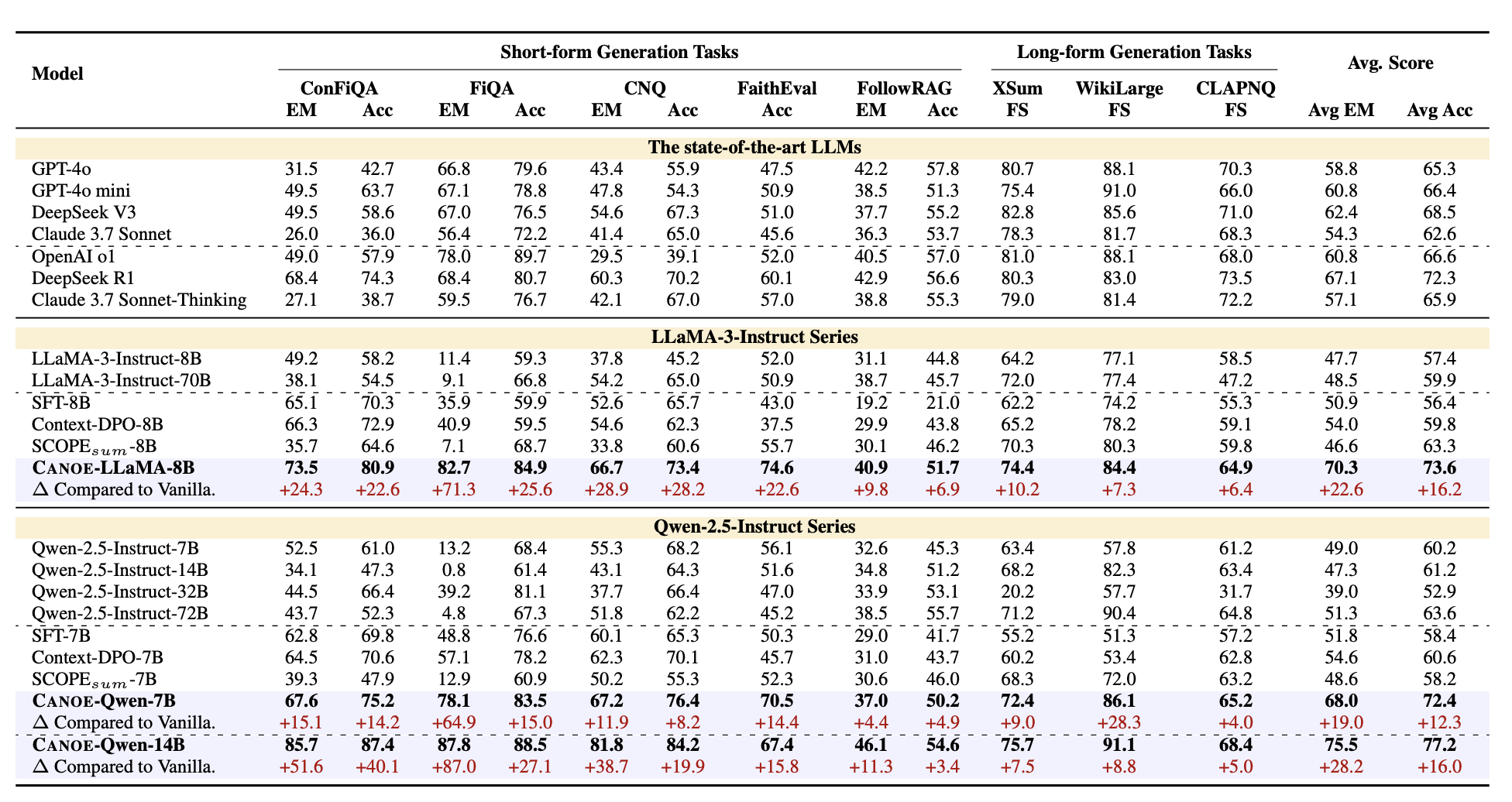
教会大型语言模型(LLM)忠实于提供的上下文对于构建可靠的信息检索系统至关重要。因此,我们提出了一个系统的框架 CANOE,以在没有人工标注的情况下,提高 LLM 在短文本和长文本生成任务中的忠实度。具体来说,我们首先合成了包含四种不同任务的短文本问答(QA)数据,以构建高质量且易于验证的训练数据,无需人工标注。此外,我们提出了 Dual-GRPO,一种基于规则的强化学习方法,该方法包含三个根据合成的短文本 QA 数据衍生的定制规则奖励,同时优化短文本和长文本响应生成。值得注意的是,Dual-GRPO 消除了手动标注偏好数据以训练奖励模型的需要,并避免了仅依赖合成的短文本 QA 数据时对短文本生成的过度优化。实验结果表明,CANOE 在 11 个不同的下游任务中极大地提高了 LLM 的忠实度,甚至超越了最先进的 LLM,例如 GPT-4o 和 OpenAI o1。


代码、数据和模型可在以下链接获取:https://github.com/S1s-Z/CANOE。