⏶4
MetaSynth:元提示驱动的智能体支架,用于多样化合成数据生成
04月17日发表
04月18日由  Haris Riaz 提交
Haris Riaz 提交
Haris Riaz 提交作者: Haris Riaz, Sourav Bhabesh, Vinayak Arannil, Miguel Ballesteros, Graham Horwood
Haris Riaz, Sourav Bhabesh, Vinayak Arannil, Miguel Ballesteros, Graham Horwood摘要
近期较小的语言模型,如Phi-3.5和Phi-4,依赖于使用更大的语言模型生成的合成数据。关于利用合成数据进行其他用例,例如将大型语言模型适应特定领域,仍然存在疑问。合成数据的一个主要局限性是多样性不足,这对其下游应用(用于改进其他模型)产生负面影响。为了解决这个问题,我们提出了MetaSynth,一种生成合成数据的方法,该方法通过元提示增强多样性,其中一个语言模型协调多个“专家”大型语言模型代理协同生成数据。仅使用2500万个由MetaSynth生成的合成数据token,我们成功地将一个训练有素的大型语言模型(Mistral-7B-v0.3)适配到两个专业领域——金融和生物医药——而不会损害生成模型在通用任务中的能力。此外,我们使用七种自动化指标评估了我们合成数据的多样性,并发现它接近大型语言模型预训练语料库的多样性。
使用MetaSynth持续预训练Mistral-7B-v0.3显著优于基础大型语言模型,在金融领域表现出高达4.08%的提升,在生物医药领域表现出高达13.75%的提升。即使模板包含先前的生成结果和不同的真实数据上下文示例,当使用模板提示生成的数据进行训练时,同一个模型也表现出性能下降。我们的研究结果表明,当使用MetaSynth时,几百万个token的多样化合成数据,无需混合任何真实数据,就足以进行有效的领域适配。

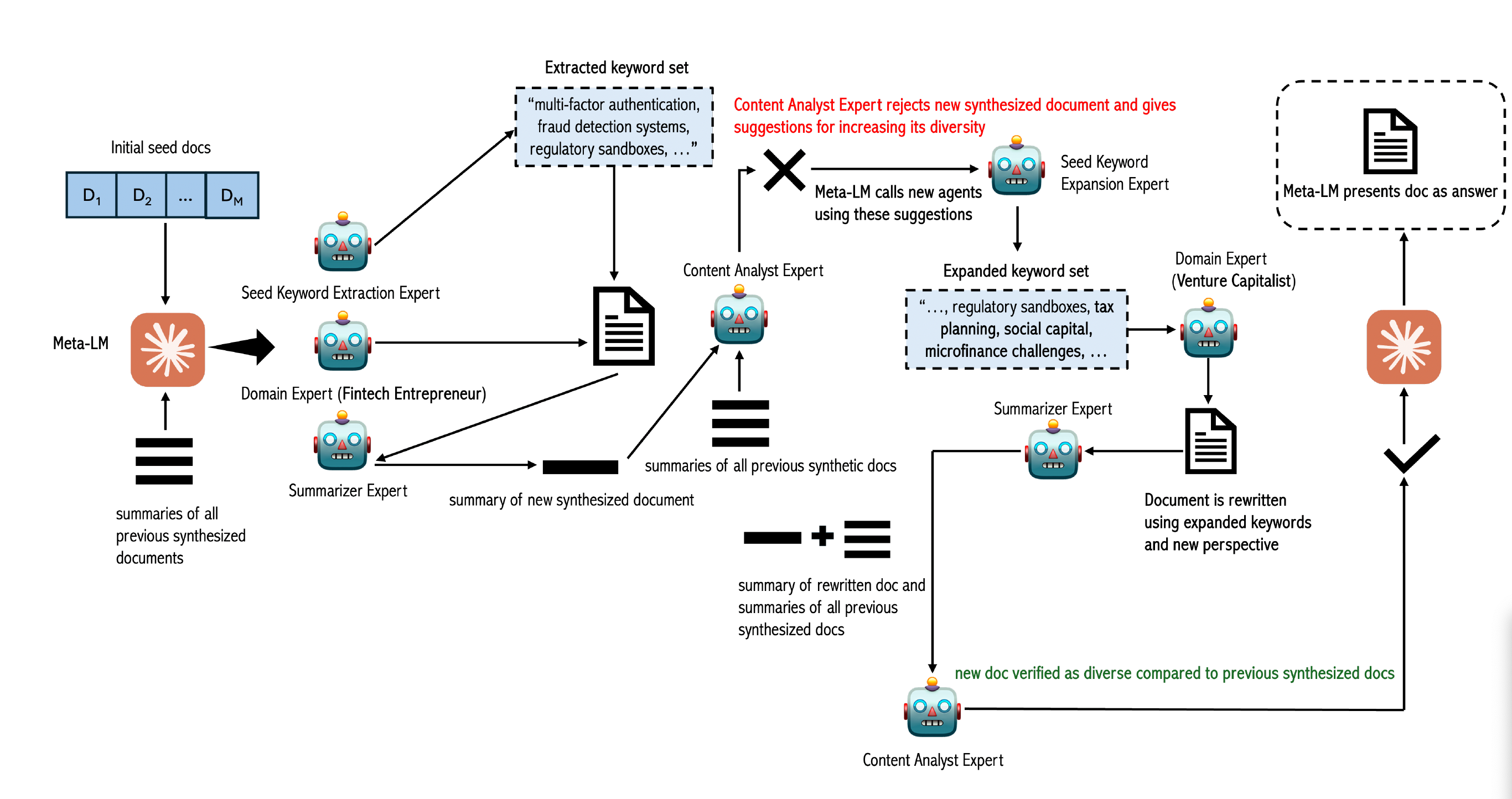
最近,像 Phi-3.5 和 Phi-4 这样的小型语言模型依赖于使用大型语言模型生成的合成数据。关于利用合成数据进行其他用例(例如,使 LLM 适应特定领域)的问题仍然存在。合成数据的一个主要限制是多样性低,这对其下游应用于改进其他模型产生负面影响。为了解决这个问题,我们提出了 METASYNTH,这是一种用于生成合成数据的方法,该方法通过元提示来增强多样性,其中语言模型协调多个“专家” LLM 代理以协作生成数据。仅使用通过 METASYNTH 生成的 2500 万个 token 的合成数据,我们成功地将一个训练有素的 LLM(Mistral-7B-v0.3)适应了金融和生物医学这两个专门领域,而没有损害所得模型在通用任务中的能力。此外,我们使用七个自动化指标评估了合成数据的多样性,发现它接近 LLM 预训练语料库的多样性。使用 METASYNTH 持续预训练 Mistral-7B-v0.3 明显优于基础 LLM,在金融领域表现出高达 4.08% 的改进,在生物医学领域表现出高达 13.75% 的改进。即使模板包含先前的生成结果和真实数据的不同上下文示例,当在模板提示生成的数据上训练时,同一模型也表现出性能下降。我们的研究结果表明,当使用 MetaSynth 时,几百万个 token 的多样化合成数据(不混合任何真实数据)足以实现有效的领域适应。