⏶10
迈向学习补全激光雷达中的一切
04月16日发表
04月17日由  Ayca Takmaz 提交
Ayca Takmaz 提交
Ayca Takmaz 提交作者: Ayca Takmaz, Cristiano Saltori, Neehar Peri, Tim Meinhardt, Riccardo de Lutio, Laura Leal-Taixé, Aljoša Ošep
Ayca Takmaz, Cristiano Saltori, Neehar Peri, Tim Meinhardt, Riccardo de Lutio, Laura Leal-Taixé, Aljoša Ošep摘要
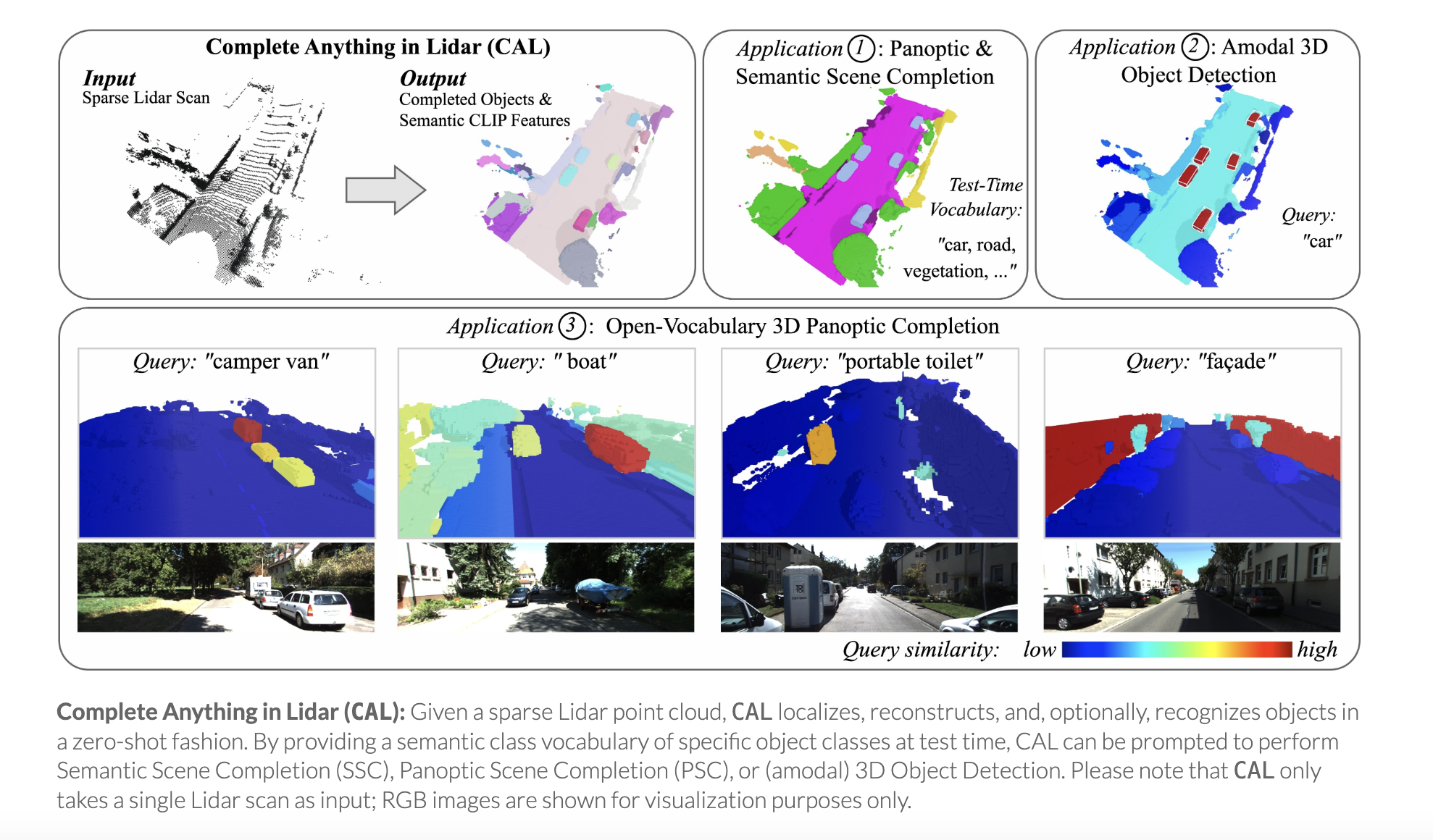
我们提出了 CAL (Complete Anything in Lidar),用于在野外进行基于激光雷达的形状补全。这与基于激光雷达的语义/全景场景补全密切相关。然而,当代方法只能从现有激光雷达数据集中标记的封闭词汇表中完成和识别对象。与此不同的是,我们的零样本方法利用来自多模态传感器序列的时间上下文来挖掘观察到的对象的对象形状和语义特征。然后将这些提炼成仅激光雷达的实例级补全和识别模型。尽管我们仅挖掘部分形状补全,但我们发现我们的提炼模型学会了从数据集中的多个此类部分观测中推断完整的对象形状。我们表明,我们的模型可以在标准基准上针对语义和全景场景补全进行提示,将对象定位为(非模态)3D 边界框,并识别超出固定类别词汇的对象。我们的项目页面是 https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
评论
Ayca Takmaz论文作者
论文提交者