AI论文精选
监督微调
⏶
294
InternVL3:探索开源多模态模型的高级训练和测试时技巧
⏶
177
关于SFT泛化性的研究:一个带有奖励修正的强化学习视角
⏶
98
Parallel-R1:通过强化学习实现并行思考
⏶
88
QwenLong-L1:迈向基于强化学习的长上下文大型推理模型
⏶
79
数学推理能否提升通用LLM能力?理解LLM推理的可迁移性
⏶
78
WebExplorer:用于训练长时序网页代理的探索与演进
⏶
74
Qwen3 Embedding:通过基础模型改进文本嵌入和重排序
⏶
73
迈向大型语言模型训练后统一视角
⏶
68
Spatial-MLLM:提升MLLM在基于视觉的空间智能方面的能力
⏶
66
赢得剪枝赌局:统一的方法,用于高效监督微调的联合样本和令牌剪枝
⏶
57
Reasoning Vectors:通过任务算术转移思维链能力
⏶
57
逆IF评估:大型语言模型能否忘记顽固的训练惯例以遵循真实指令?
⏶
56
革新扩散大语言模型的强化学习框架
⏶
54
DeepCritic:使用大型语言模型进行审慎批判
⏶
52
Phi-4-reasoning 技术报告
⏶
52
UniVG-R1: 结合强化学习的推理引导通用视觉定位
⏶
51
TruthRL:通过强化学习激励诚实的LLM
⏶
50
如何训练您的LLM网络代理:一项统计诊断
⏶
49
SpeakerVid-5M:一个用于音视频双人互动生成的大规模高质量数据集
⏶
48
Phi-4-Mini-Reasoning:探索小型推理语言模型在数学领域的极限
⏶
47
ToolRL:奖励是工具学习的全部需求
⏶
47
Bee:一个高质量语料库和全栈套件,用于解锁高级全开源 MLLM
⏶
46
StreamingVLM: 实时理解无限视频流
⏶
44
Video-LMM 训练后:深入了解大型多模态模型的视频推理
⏶
43
CriticLean: 评论家引导的强化学习,用于数学形式化
⏶
42
Llama-Nemotron: 高效推理模型
⏶
42
Mol-R1:迈向分子发现中明确的长链思维推理
⏶
41
OpenThinkIMG:通过视觉工具强化学习来学习用图像思考
⏶
37
LiveCC:大规模使用流式语音转录学习视频大型语言模型
⏶
36
对比偏好优化:在机器翻译中突破LLM性能的界限
⏶
36
DeepSeek-R1发布100天后:推理语言模型的复现研究及更多方向综述
⏶
36
通过带有冷启动的强化学习推进多模态推理
⏶
36
cadrille: 基于在线强化学习的多模态 CAD 重建
⏶
36
RLinf-VLA:一个统一高效的 VLA+RL 训练框架
⏶
35
MM-IFEngine:面向多模态指令跟随
⏶
33
PIPer:通过在线强化学习实现设备端环境设置
⏶
32
WebDancer: 迈向自主信息寻求代理
⏶
31
SQL-R1:通过强化学习训练自然语言到SQL的推理模型
⏶
31
TaskCraft:自动生成代理任务
⏶
31
CapRL:通过强化学习激发密集图像字幕能力
⏶
29
SFT 或 RL? 训练类似 R1 的推理大型视觉-语言模型的早期研究
⏶
29
迈向通用检索增强生成的混合模态检索
⏶
27
AutoTriton:在LLM中通过强化学习实现自动化Triton编程
⏶
27
BrowserAgent:利用人类启发式网页浏览行为构建网页代理
⏶
27
不要仅仅微调代理,要调整环境
⏶
26
AceReason-Nemotron 1.1:SFT与RL协同赋能数学与代码推理
⏶
26
当今的大型语言模型准备好解释幸福概念了吗?
⏶
25
Jigsaw-R1:基于拼图的规则化视觉强化学习研究
⏶
25
多样性增强主观问题推理
⏶
24
VideoScore2:生成视频评估中,三思而后评
⏶
24
初次尝试很重要:重新审视推理模型中反思的作用
⏶
23
Satori-SWE:面向样本高效软件工程的进化式测试时缩放
⏶
22
手机自动化中的LLM驱动GUI智能体:进展与前景综述
⏶
22
UniRL: 基于监督学习与强化学习的自我改进统一多模态模型
⏶
22
ShotBench: 视觉-语言模型中的专家级电影理解
⏶
21
Resa:通过SAEs实现透明推理模型
⏶
21
用于视觉-语言慢思考推理的半脱策略强化学习
⏶
21
保持在最佳状态:通过能力自适应提示脚手架实现响应式推理演化
⏶
21
思维火花!:推理模型在训练后出现的注意力头
⏶
20
OmniCaptioner:一统天下的图像描述器
⏶
20
LeetCodeDataset:用于代码 LLM 的稳健评估和高效训练的时间数据集
⏶
20
StepWiser:用于更明智推理的逐步生成式判官
⏶
19
MLE-Dojo:赋能机器学习工程中大型语言模型智能体的交互式环境
⏶
19
重塑:借助大语言模型中的强化学习来降低可扩展形式化软件验证中的人为先验——一项关于Dafny的初步研究
⏶
19
学习对齐,对齐以学:自优化对齐的统一方法
⏶
19
平静在风暴之前:解锁用于优化建模的原生推理
⏶
18
大型语言模型能否帮助多模态语言分析?MMLA:综合基准
⏶
18
AM-Thinking-v1:推进 32B 规模推理能力的前沿
⏶
18
穿越山谷:小型语言模型长CoT(思维链)高效训练之路
⏶
18
QFFT:用于自适应推理的无问微调
⏶
18
通过批评-编辑强化学习实现忠实和可控的个性化
⏶
17
迈向 LLM 中的安全推理:AI 智能体式审议用于策略嵌入式 CoT 数据创建
⏶
17
CoRT:思维中的代码集成推理
⏶
17
SearchInstruct:通过基于检索的指令数据集创建增强领域自适应
⏶
16
Aryabhata: 一个专注于JEE数学的考试导向型语言模型
⏶
15
X-Reasoner:面向跨模态和领域的通用推理
⏶
15
对先验的深思:大型语言模型在知识图谱上的可信推理
⏶
15
以工具取代思考,使小型语言模型能够进行推理
⏶
15
MedReseacher-R1:通过知识知悉的轨迹合成框架实现专家级医学深度研究
⏶
14
SimpleAR:通过预训练、SFT和RL推动自回归视觉生成的前沿
⏶
14
SRFT:一种结合监督学习和强化学习微调的单阶段推理方法
⏶
14
OpenCodeReasoning-II:一种通过自我批判实现简单测试时缩放的方法
⏶
13
如何增强大型推理模型的安全性:一项实证研究
⏶
13
完成胜于完美:通过结构化多轮分解解锁高效推理
⏶
13
RefCritic:使用细化反馈训练长链式思维批判模型
⏶
13
分析监督微调对模型在 Token 和参数层级知识的影响
⏶
13
通过自演化偏好学习实现有效的工具集成推理
⏶
12
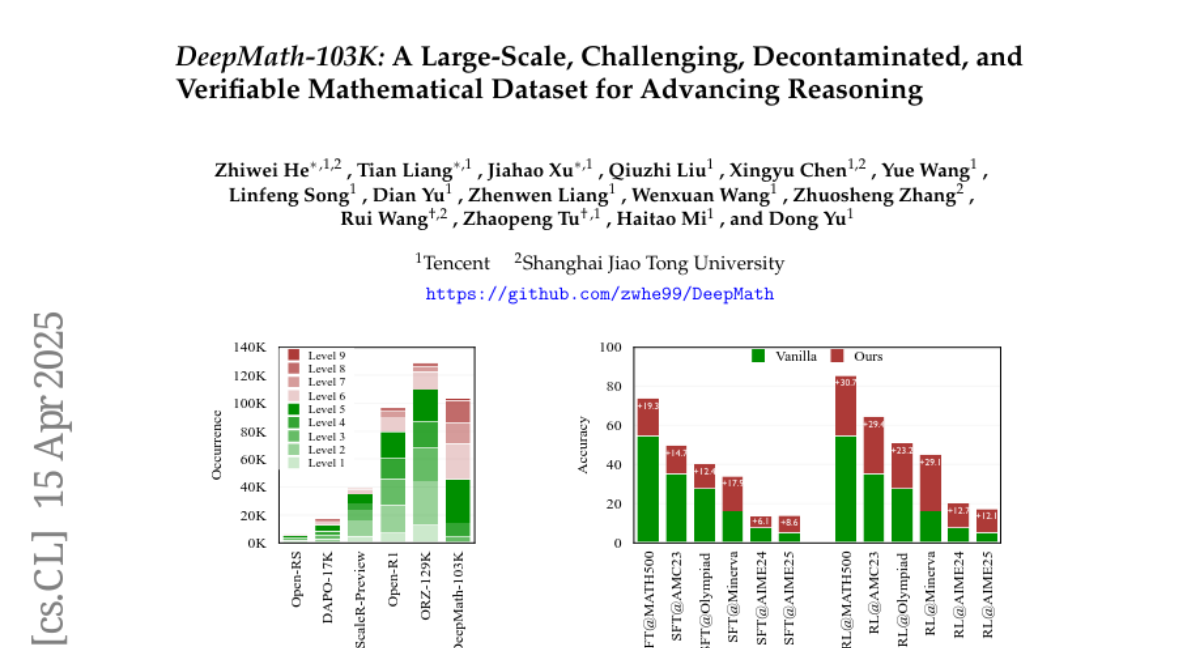
DeepMath-103K:一个大规模、具有挑战性、已净化且可验证的数学数据集,用于推进推理
⏶
11
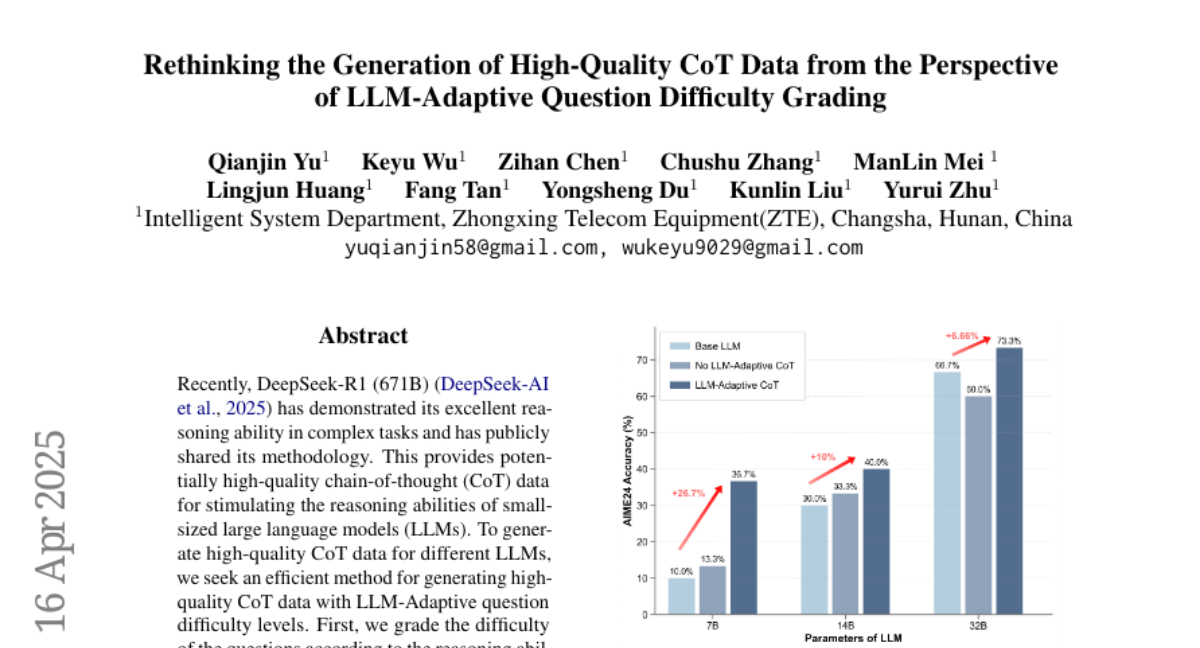
从 LLM 自适应的问题难度分级的角度,重新思考高质量 CoT 数据的生成
⏶
11
用于矢量图形生成的渲染感知强化学习
⏶
11
像经济学家一样推理:对经济问题进行后训练可诱导大型语言模型 (LLMs) 产生战略性泛化
⏶
11
基于多轮接地强化学习的高分辨率视觉推理
⏶
11
RL在自回归图像编辑中的前景
⏶
11
QUASAR:通过基于代理的强化学习使用工具增强的 LLM 进行量子汇编代码生成
⏶
11
Patch-as-Decodable-Token:迈向 MLLM 中统一的多模态视觉任务
⏶
11
ssToken:用于 LLM 微调的自适应和语义感知 Token 选择
⏶
10
合成数据 RL:任务定义就够了
⏶
10
STAR-R1:通过强化多模态大语言模型实现空间变换推理
⏶
10
ReasonGen-R1:基于SFT和RL的自回归图像生成模型思维链(CoT)
⏶
10
构建数学大语言模型的实用两阶段方案:利用SFT最大化准确率,以强化学习提升效率
⏶
9
复合AI系统优化:方法、挑战与未来方向综述
⏶
9
TeleChat2、TeleChat2.5和T1技术报告
⏶
9
InfiAlign: 一种可扩展且样本高效的框架,用于对齐大型语言模型以增强推理能力
⏶
9
强化学习在语言模型规划中的益处与陷阱:理论视角
⏶
8
Think-RM:在生成式奖励模型中实现长周期推理