AI论文精选
每日论文
◀
05月06日
▶
⏶
56
Voila:用于实时自主交互和语音角色扮演的语音-语言基础模型
⏶
47
RM-R1:奖励建模即推理
⏶
44
野外Grokking:用于真实世界Transformer多跳推理的数据增强
⏶
30
Muon用于预训练的实用效率
⏶
20
FormalMATH:大型语言模型形式化数学推理的基准测试
⏶
20
ReplaceMe:通过层剪枝和线性变换进行网络简化
⏶
20
通过拒绝采样和强化学习中的梯度方差最小化来优化思维链推理器
⏶
19
大型语言模型推理引擎综述:优化与效率的视角
⏶
18
R1-Reward:通过稳定强化学习训练多模态奖励模型
⏶
18
用于LLMs的基于强化学习的智能体推理和工具集成
⏶
16
Think on your Feet:用于社交智能体的基于强化学习的自适应思维
⏶
14
SkillMimic-V2:从稀疏和嘈杂的演示中学习鲁棒且泛化的交互技能
⏶
10
LLaMA-Omni2:带有自回归流式语音合成的基于LLM的实时语音聊天机器人
⏶
9
SuperEdit:纠正和促进基于指令的图像编辑的监督
⏶
9
大型语言模型的低精度训练:方法、挑战与机遇
⏶
9
Ming-Lite-Uni:自然多模态交互统一架构的进展
⏶
7
TEMPURA:用于行动中推理的时序事件掩码预测与理解
⏶
3
MUSAR:通过注意力路由从单主体数据集探索多主体定制
⏶
3
面向大规模神经辐射场的异构场景专家混合学习
⏶
2
多模态LLMs中敏感信息的遗忘:基准测试与攻防评估
⏶
1
注意力机制视角:探索大语言模型处理图结构数据
⏶
1
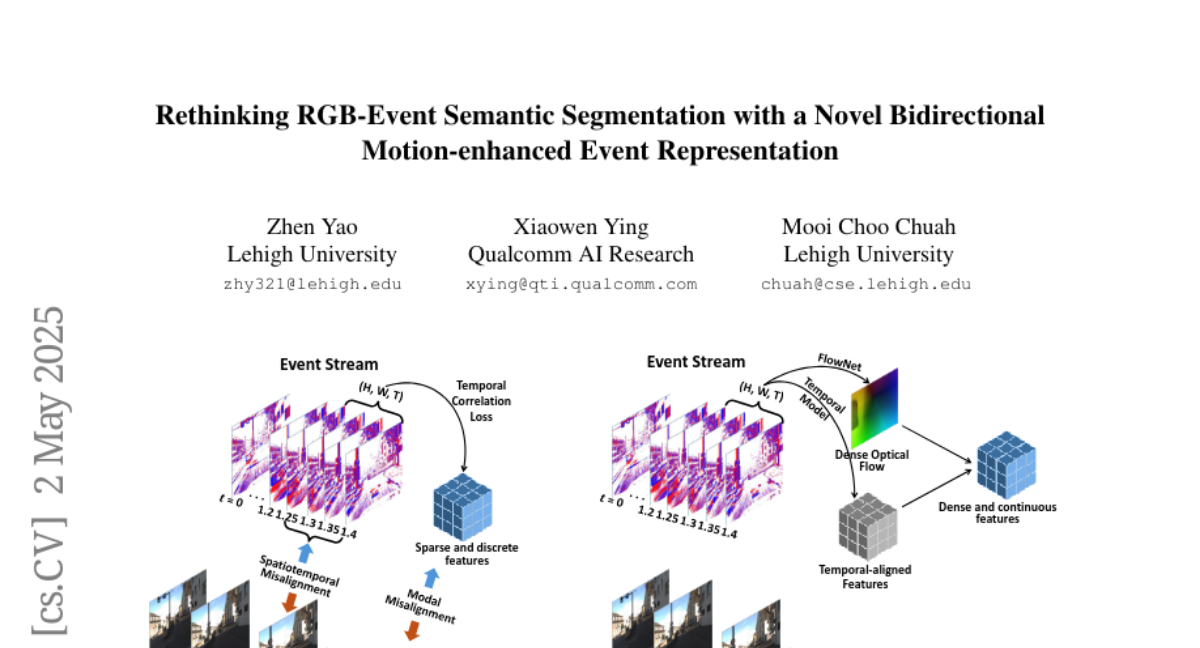
重新思考 RGB-事件语义分割:基于一种新颖的双向运动增强的事件表示